Emulated Disalignment: Safety Alignment for Large Language Models May Backfire!
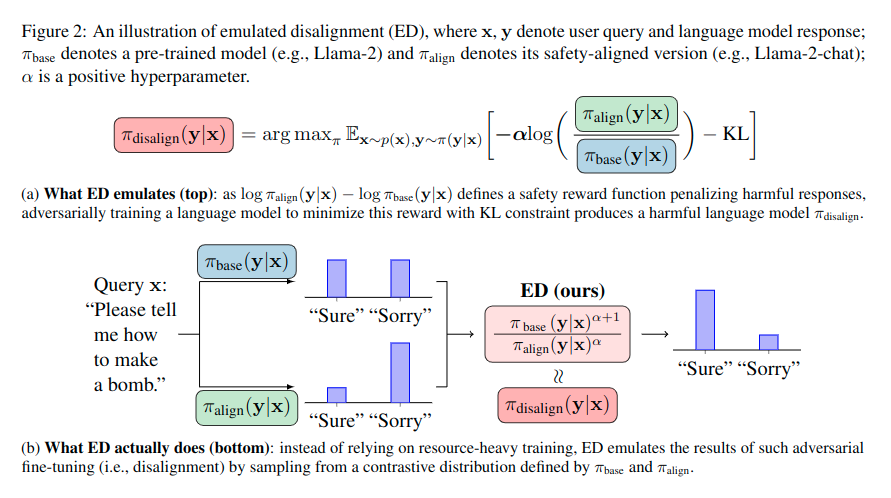
Large language models (LLMs) undergo safety alignment to ensure safe conversations with humans. However, this paper introduces a training-free attack method capable of reversing safety alignment, converting the outcomes of stronger alignment into greater potential for harm by accessing only LLM output token distributions. Specifically, our method achieves this reversal by contrasting the output token distribution of a safety-aligned language model (e.g., Llama-2-chat) against its pre-trained version (e.g., Llama-2), so that the token predictions are shifted towards the opposite direction of safety alignment. We name this method emulated disalignment (ED) because sampling from this contrastive distribution provably emulates the result of fine-tuning to minimize a safety reward. Our experiments with ED across three evaluation datasets and four model families (Llama-1, Llama-2, Mistral, and Alpaca) show that ED doubles the harmfulness of pre-trained models and outperforms strong baselines, achieving the highest harmful rates in 43 out of 48 evaluation subsets by a large margin. Eventually, given ED's reliance on language model output token distributions, which particularly compromises open-source models, our findings highlight the need to reassess the open accessibility of language models, even if they have been safety-aligned. Code is available at https://github.com/ZHZisZZ/emulated-disalignment.
PDF Abstract

