MR-GSM8K: A Meta-Reasoning Benchmark for Large Language Model Evaluation
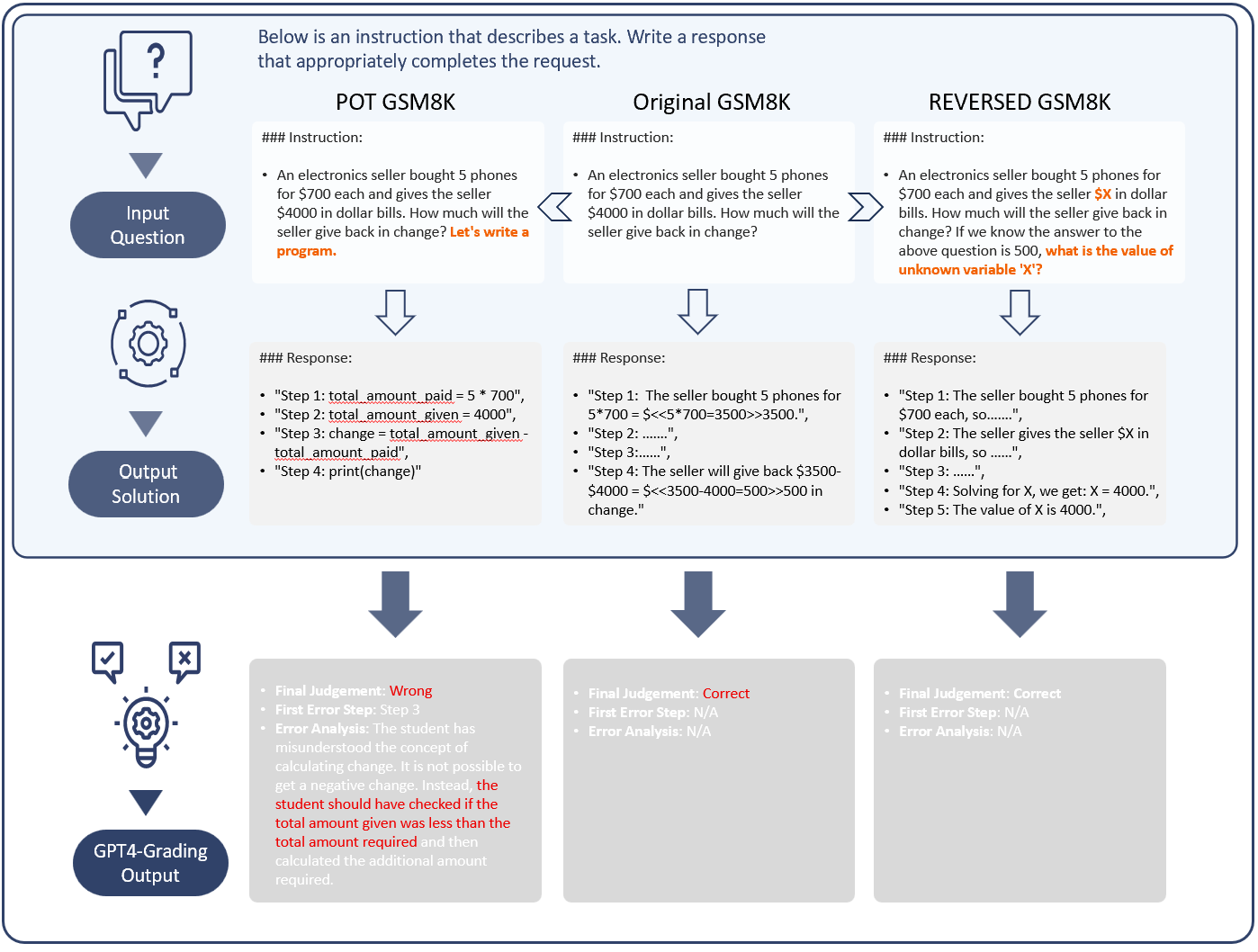
In this work, we introduce a novel evaluation paradigm for Large Language Models (LLMs) that compels them to transition from a traditional question-answering role, akin to a student, to a solution-scoring role, akin to a teacher. This paradigm, focusing on "reasoning about reasoning," hence termed meta-reasoning, shifts the emphasis from result-oriented assessments, which often neglect the reasoning process, to a more comprehensive evaluation that effectively distinguishes between the cognitive capabilities of different models. By applying this paradigm in the GSM8K dataset, we have developed the MR-GSM8K benchmark. Our extensive analysis includes several state-of-the-art models from both open-source and commercial domains, uncovering fundamental deficiencies in their training and evaluation methodologies. Notably, while models like Deepseek-v2 and Claude3-Sonnet closely competed with GPT-4 in GSM8K, their performance disparities expanded dramatically in MR-GSM8K, with differences widening to over 20 absolute points, underscoring the significant challenge posed by our meta-reasoning approach.
PDF Abstract



 GSM8K
GSM8K
 MATH
MATH
