Search Results for author:
Found 15 papers, 9 papers with code
VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion
To enable such capability in AI systems, we propose VoxFormer, a Transformer-based semantic scene completion framework that can output complete 3D volumetric semantics from only 2D images.

 3D Semantic Scene Completion from a single RGB image
3D Semantic Scene Completion from a single RGB image
 Depth Estimation
Depth Estimation
Spacetime Surface Regularization for Neural Dynamic Scene Reconstruction
We propose an algorithm, 4DRegSDF, for the spacetime surface regularization to improve the fidelity of neural rendering and reconstruction in dynamic scenes.

PeRFception: Perception using Radiance Fields
The recent progress in implicit 3D representation, i. e., Neural Radiance Fields (NeRFs), has made accurate and photorealistic 3D reconstruction possible in a differentiable manner.

Neural Scene Representation for Locomotion on Structured Terrain
We propose a learning-based method to reconstruct the local terrain for locomotion with a mobile robot traversing urban environments.
ACID: Action-Conditional Implicit Visual Dynamics for Deformable Object Manipulation
Manipulating volumetric deformable objects in the real world, like plush toys and pizza dough, bring substantial challenges due to infinite shape variations, non-rigid motions, and partial observability.


Putting 3D Spatially Sparse Networks on a Diet
3D neural networks have become prevalent for many 3D vision tasks including object detection, segmentation, registration, and various perception tasks for 3D inputs.

Self-Calibrating Neural Radiance Fields
We also propose a new geometric loss function, viz., projected ray distance loss, to incorporate geometric consistency for complex non-linear camera models.
DiscoBox: Weakly Supervised Instance Segmentation and Semantic Correspondence from Box Supervision
We introduce DiscoBox, a novel framework that jointly learns instance segmentation and semantic correspondence using bounding box supervision.

Generative Sparse Detection Networks for 3D Single-shot Object Detection
3D object detection has been widely studied due to its potential applicability to many promising areas such as robotics and augmented reality.
 Ranked #6 on
3D Object Detection
on S3DIS
Ranked #6 on
3D Object Detection
on S3DIS

High-dimensional Convolutional Networks for Geometric Pattern Recognition
Many problems in science and engineering can be formulated in terms of geometric patterns in high-dimensional spaces.
Deep Global Registration
We present Deep Global Registration, a differentiable framework for pairwise registration of real-world 3D scans.
 Ranked #2 on
Point Cloud Registration
on KITTI (FCGF setting)
Ranked #2 on
Point Cloud Registration
on KITTI (FCGF setting)

SceneCAD: Predicting Object Alignments and Layouts in RGB-D Scans
We present a novel approach to reconstructing lightweight, CAD-based representations of scanned 3D environments from commodity RGB-D sensors.
Fully Convolutional Geometric Features
Extracting geometric features from 3D scans or point clouds is the first step in applications such as registration, reconstruction, and tracking.
 Ranked #1 on
3D Feature Matching
on 3DMatch Benchmark
Ranked #1 on
3D Feature Matching
on 3DMatch Benchmark
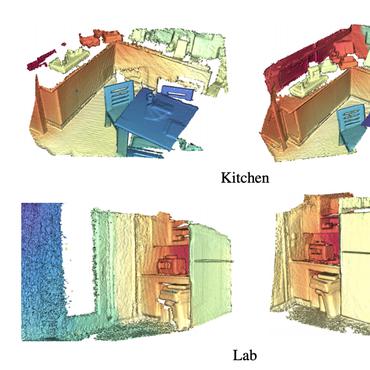

4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks
To overcome challenges in the 4D space, we propose the hybrid kernel, a special case of the generalized sparse convolution, and the trilateral-stationary conditional random field that enforces spatio-temporal consistency in the 7D space-time-chroma space.
 Ranked #1 on
Robust 3D Semantic Segmentation
on WOD-C
Ranked #1 on
Robust 3D Semantic Segmentation
on WOD-C
 4D Spatio Temporal Semantic Segmentation
4D Spatio Temporal Semantic Segmentation
 Robust 3D Semantic Segmentation
Robust 3D Semantic Segmentation
DeformNet: Free-Form Deformation Network for 3D Shape Reconstruction from a Single Image
We evaluate our approach on the ShapeNet dataset and show that - (a) the Free-Form Deformation layer is a powerful new building block for Deep Learning models that manipulate 3D data (b) DeformNet uses this FFD layer combined with shape retrieval for smooth and detail-preserving 3D reconstruction of qualitatively plausible point clouds with respect to a single query image (c) compared to other state-of-the-art 3D reconstruction methods, DeformNet quantitatively matches or outperforms their benchmarks by significant margins.

