Search Results for author:
Found 9 papers, 2 papers with code
Improved Prognostic Prediction of Pancreatic Cancer Using Multi-Phase CT by Integrating Neural Distance and Texture-Aware Transformer
Pancreatic ductal adenocarcinoma (PDAC) is a highly lethal cancer in which the tumor-vascular involvement greatly affects the resectability and, thus, overall survival of patients.
Cluster-Induced Mask Transformers for Effective Opportunistic Gastric Cancer Screening on Non-contrast CT Scans
In our experiments, the proposed method achieves a sensitivity of 85. 0% and specificity of 92. 6% for detecting gastric tumors on a hold-out test set consisting of 100 patients with cancer and 148 normal.

Devil is in the Queries: Advancing Mask Transformers for Real-world Medical Image Segmentation and Out-of-Distribution Localization
Real-world medical image segmentation has tremendous long-tailed complexity of objects, among which tail conditions correlate with relatively rare diseases and are clinically significant.

Region-Aware Metric Learning for Open World Semantic Segmentation via Meta-Channel Aggregation
Therefore, we propose a method called region-aware metric learning (RAML), which first separates the regions of the images and generates region-aware features for further metric learning.

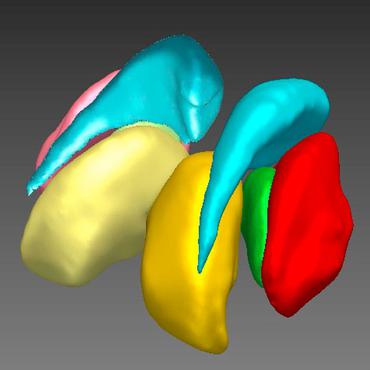
CrossMoDA 2021 challenge: Benchmark of Cross-Modality Domain Adaptation techniques for Vestibular Schwannoma and Cochlea Segmentation
The aim was to automatically perform unilateral VS and bilateral cochlea segmentation on hrT2 as provided in the testing set (N=137).

Layer-Parallel Training of Residual Networks with Auxiliary-Variable Networks
Gradient-based methods for the distributed training of residual networks (ResNets) typically require a forward pass of the input data, followed by back-propagating the error gradient to update model parameters, which becomes time-consuming as the network goes deeper.

Unsupervised Domain Adaptation in Semantic Segmentation Based on Pixel Alignment and Self-Training
This paper proposes an unsupervised cross-modality domain adaptation approach based on pixel alignment and self-training.

Layer-Parallel Training of Residual Networks with Auxiliary Variables
Backpropagation algorithm is indispensable for training modern residual networks (ResNets) and usually tends to be time-consuming due to its inherent algorithmic lockings.
A Practical Layer-Parallel Training Algorithm for Residual Networks
Gradient-based algorithms for training ResNets typically require a forward pass of the input data, followed by back-propagating the objective gradient to update parameters, which are time-consuming for deep ResNets.
