Search Results for author:
Found 92 papers, 44 papers with code
Learning Human Motion from Monocular Videos via Cross-Modal Manifold Alignment
Learning 3D human motion from 2D inputs is a fundamental task in the realms of computer vision and computer graphics.
GeneAvatar: Generic Expression-Aware Volumetric Head Avatar Editing from a Single Image
Recently, we have witnessed the explosive growth of various volumetric representations in modeling animatable head avatars.
CG-SLAM: Efficient Dense RGB-D SLAM in a Consistent Uncertainty-aware 3D Gaussian Field
Recently neural radiance fields (NeRF) have been widely exploited as 3D representations for dense simultaneous localization and mapping (SLAM).


Vox-Fusion++: Voxel-based Neural Implicit Dense Tracking and Mapping with Multi-maps
In this paper, we introduce Vox-Fusion++, a multi-maps-based robust dense tracking and mapping system that seamlessly fuses neural implicit representations with traditional volumetric fusion techniques.
3D-SceneDreamer: Text-Driven 3D-Consistent Scene Generation
Text-driven 3D scene generation techniques have made rapid progress in recent years.
Boosting Image Restoration via Priors from Pre-trained Models
Pre-trained models with large-scale training data, such as CLIP and Stable Diffusion, have demonstrated remarkable performance in various high-level computer vision tasks such as image understanding and generation from language descriptions.


Multi-View Neural 3D Reconstruction of Micro-/Nanostructures with Atomic Force Microscopy
However, conventional AFM scanning struggles to reconstruct complex 3D micro-/nanostructures precisely due to limitations such as incomplete sample topography capturing and tip-sample convolution artifacts.

Neural Rendering and Its Hardware Acceleration: A Review
On this basis, we analyze the common requirements of neural rendering pipeline for hardware acceleration and the characteristics of the current hardware acceleration architecture, and then discuss the design challenges of neural rendering processor architecture.
PNeRFLoc: Visual Localization with Point-based Neural Radiance Fields
In this paper, we propose a novel visual localization framework, \ie, PNeRFLoc, based on a unified point-based representation.

EasyVolcap: Accelerating Neural Volumetric Video Research
Volumetric video is a technology that digitally records dynamic events such as artistic performances, sporting events, and remote conversations.
Holistic Inverse Rendering of Complex Facade via Aerial 3D Scanning
In this work, we use multi-view aerial images to reconstruct the geometry, lighting, and material of facades using neural signed distance fields (SDFs).
RD-VIO: Robust Visual-Inertial Odometry for Mobile Augmented Reality in Dynamic Environments
In this work, we design a novel visual-inertial odometry (VIO) system called RD-VIO to handle both of these two problems.
4K4D: Real-Time 4D View Synthesis at 4K Resolution
Experiments show that our representation can be rendered at over 400 FPS on the DNA-Rendering dataset at 1080p resolution and 80 FPS on the ENeRF-Outdoor dataset at 4K resolution using an RTX 4090 GPU, which is 30x faster than previous methods and achieves the state-of-the-art rendering quality.
FuseSR: Super Resolution for Real-time Rendering through Efficient Multi-resolution Fusion
To mitigate this problem, one of the most popular solutions is to render images at a low resolution to reduce rendering overhead, and then manage to accurately upsample the low-resolution rendered image to the target resolution, a. k. a.

Im4D: High-Fidelity and Real-Time Novel View Synthesis for Dynamic Scenes
This paper aims to tackle the challenge of dynamic view synthesis from multi-view videos.
Hierarchical Generation of Human-Object Interactions with Diffusion Probabilistic Models
This paper presents a novel approach to generating the 3D motion of a human interacting with a target object, with a focus on solving the challenge of synthesizing long-range and diverse motions, which could not be fulfilled by existing auto-regressive models or path planning-based methods.
Depth Completion with Multiple Balanced Bases and Confidence for Dense Monocular SLAM
In this paper, we propose a novel method that integrates a light-weight depth completion network into a sparse SLAM system using a multi-basis depth representation, so that dense mapping can be performed online even on a mobile phone.

Multi-Modal Neural Radiance Field for Monocular Dense SLAM with a Light-Weight ToF Sensor
Specifically, we propose a multi-modal implicit scene representation that supports rendering both the signals from the RGB camera and light-weight ToF sensor which drives the optimization by comparing with the raw sensor inputs.

Graph-based Asynchronous Event Processing for Rapid Object Recognition
Different from traditional video cameras, event cameras capture asynchronous events stream in which each event encodes pixel location, trigger time, and the polarity of the brightness changes.

Relightable and Animatable Neural Avatar from Sparse-View Video
Based on the HDQ algorithm, we leverage sphere tracing to efficiently estimate the surface intersection and light visibility.
Mirror-NeRF: Learning Neural Radiance Fields for Mirrors with Whitted-Style Ray Tracing
Recently, Neural Radiance Fields (NeRF) has exhibited significant success in novel view synthesis, surface reconstruction, etc.
Dyn-E: Local Appearance Editing of Dynamic Neural Radiance Fields
We extensively evaluate our approach on various scenes and show that our approach achieves spatially and temporally consistent editing results.
Detector-Free Structure from Motion
We propose a new detector-free SfM framework to draw benefits from the recent success of detector-free matchers to avoid the early determination of keypoints, while solving the multi-view inconsistency issue of detector-free matchers.

Learning Human Mesh Recovery in 3D Scenes
We present a novel method for recovering the absolute pose and shape of a human in a pre-scanned scene given a single image.
AutoRecon: Automated 3D Object Discovery and Reconstruction
A fully automated object reconstruction pipeline is crucial for digital content creation.
Representing Volumetric Videos as Dynamic MLP Maps
This paper introduces a novel representation of volumetric videos for real-time view synthesis of dynamic scenes.
CF-Font: Content Fusion for Few-shot Font Generation
Content and style disentanglement is an effective way to achieve few-shot font generation.
SINE: Semantic-driven Image-based NeRF Editing with Prior-guided Editing Field
Despite the great success in 2D editing using user-friendly tools, such as Photoshop, semantic strokes, or even text prompts, similar capabilities in 3D areas are still limited, either relying on 3D modeling skills or allowing editing within only a few categories.
PATS: Patch Area Transportation with Subdivision for Local Feature Matching
However, estimating scale differences between these patches is non-trivial since the scale differences are determined by both relative camera poses and scene structures, and thus spatially varying over image pairs.

I$^2$-SDF: Intrinsic Indoor Scene Reconstruction and Editing via Raytracing in Neural SDFs
In this work, we present I$^2$-SDF, a new method for intrinsic indoor scene reconstruction and editing using differentiable Monte Carlo raytracing on neural signed distance fields (SDFs).
BlinkFlow: A Dataset to Push the Limits of Event-based Optical Flow Estimation
BlinkSim consists of a configurable rendering engine and a flexible engine for event data simulation.
Perceiving Unseen 3D Objects by Poking the Objects
We present a novel approach to interactive 3D object perception for robots.
Learning Neural Volumetric Representations of Dynamic Humans in Minutes
In this paper, we propose a novel method for learning neural volumetric videos of dynamic humans from sparse view videos in minutes with competitive visual quality.
EC-SfM: Efficient Covisibility-based Structure-from-Motion for Both Sequential and Unordered Images
Based on this general image connection, we propose a unified framework to efficiently reconstruct sequential images, unordered images, and the mixture of these two.
OnePose++: Keypoint-Free One-Shot Object Pose Estimation without CAD Models
We propose a new method for object pose estimation without CAD models.
I2-SDF: Intrinsic Indoor Scene Reconstruction and Editing via Raytracing in Neural SDFs
Further, we propose to decompose the neural radiance field into spatially-varying material of the scene as a neural field through surface-based, differentiable Monte Carlo raytracing and emitter semantic segmentations, which enables physically based and photorealistic scene relighting and editing applications.
DPS-Net: Deep Polarimetric Stereo Depth Estimation
Stereo depth estimation usually struggles to deal with textureless scenes for both traditional and learning-based methods due to the inherent dependence on image correspondence matching.
Improving Feature-based Visual Localization by Geometry-Aided Matching
We apply GAM to a new hierarchical visual localization pipeline and show that GAM can effectively improve the robustness and accuracy of localization.

Learning-based Inverse Rendering of Complex Indoor Scenes with Differentiable Monte Carlo Raytracing
Indoor scenes typically exhibit complex, spatially-varying appearance from global illumination, making inverse rendering a challenging ill-posed problem.
IntrinsicNeRF: Learning Intrinsic Neural Radiance Fields for Editable Novel View Synthesis
Existing inverse rendering combined with neural rendering methods can only perform editable novel view synthesis on object-specific scenes, while we present intrinsic neural radiance fields, dubbed IntrinsicNeRF, which introduce intrinsic decomposition into the NeRF-based neural rendering method and can extend its application to room-scale scenes.

DELTAR: Depth Estimation from a Light-weight ToF Sensor and RGB Image
Light-weight time-of-flight (ToF) depth sensors are small, cheap, low-energy and have been massively deployed on mobile devices for the purposes like autofocus, obstacle detection, etc.
Vox-Surf: Voxel-based Implicit Surface Representation
Virtual content creation and interaction play an important role in modern 3D applications such as AR and VR.
NeuMesh: Learning Disentangled Neural Mesh-based Implicit Field for Geometry and Texture Editing
Very recently neural implicit rendering techniques have been rapidly evolved and shown great advantages in novel view synthesis and 3D scene reconstruction.

QuickPose: Real-time Multi-view Multi-person Pose Estimation in Crowded Scenes
The key challenge of this problem is to efficiently match 2D observations across multiple views.
 Ranked #2 on
3D Multi-Person Pose Estimation
on Shelf
Ranked #2 on
3D Multi-Person Pose Estimation
on Shelf

DeFlowSLAM: Self-Supervised Scene Motion Decomposition for Dynamic Dense SLAM
We present a novel dual-flow representation of scene motion that decomposes the optical flow into a static flow field caused by the camera motion and another dynamic flow field caused by the objects' movements in the scene.
Factorized and Controllable Neural Re-Rendering of Outdoor Scene for Photo Extrapolation
Expanding an existing tourist photo from a partially captured scene to a full scene is one of the desired experiences for photography applications.
PVO: Panoptic Visual Odometry
We present PVO, a novel panoptic visual odometry framework to achieve more comprehensive modeling of the scene motion, geometry, and panoptic segmentation information.
VIP-SLAM: An Efficient Tightly-Coupled RGB-D Visual Inertial Planar SLAM
Even if the plane parameters are involved in the optimization, we effectively simplify the back-end map by using planar structures.
Neural 3D Scene Reconstruction with the Manhattan-world Assumption
Based on the Manhattan-world assumption, planar constraints are employed to regularize the geometry in floor and wall regions predicted by a 2D semantic segmentation network.
Neural Rendering in a Room: Amodal 3D Understanding and Free-Viewpoint Rendering for the Closed Scene Composed of Pre-Captured Objects
We, as human beings, can understand and picture a familiar scene from arbitrary viewpoints given a single image, whereas this is still a grand challenge for computers.
CNN LEGO: Disassembling and Assembling Convolutional Neural Network
the feature maps are adopted to locate the critical features in each layer.

Hybrid Mesh-neural Representation for 3D Transparent Object Reconstruction
We propose a novel method to reconstruct the 3D shapes of transparent objects using hand-held captured images under natural light conditions.

Animatable Implicit Neural Representations for Creating Realistic Avatars from Videos
Some recent works have proposed to decompose a non-rigidly deforming scene into a canonical neural radiance field and a set of deformation fields that map observation-space points to the canonical space, thereby enabling them to learn the dynamic scene from images.
Normal and Visibility Estimation of Human Face from a Single Image
Recent work on the intrinsic image of humans starts to consider the visibility of incident illumination and encodes the light transfer function by spherical harmonics.
Hybrid Tracker with Pixel and Instance for Video Panoptic Segmentation
HybridTracker performs pixel tracker and instance tracker in parallel to obtain the association matrices, which are fused into a matching matrix.
SelfRecon: Self Reconstruction Your Digital Avatar from Monocular Video
Meanwhile, the explicit mesh is updated periodically to adjust its topology changes, and a consistency loss is designed to match both representations.
NICE-SLAM: Neural Implicit Scalable Encoding for SLAM
Neural implicit representations have recently shown encouraging results in various domains, including promising progress in simultaneous localization and mapping (SLAM).
Geometry-aware Two-scale PIFu Representation for Human Reconstruction
Our key idea is to exploit the complementary properties of depth denoising and 3D reconstruction, for learning a two-scale PIFu representation to reconstruct high-frequency facial details and consistent bodies separately.
Efficient Neural Radiance Fields for Interactive Free-viewpoint Video
We propose a novel scene representation, called ENeRF, for the fast creation of interactive free-viewpoint videos.

LatentHuman: Shape-and-Pose Disentangled Latent Representation for Human Bodies
In this work, we propose a novel neural implicit representation for the human body, which is fully differentiable and optimizable with disentangled shape and pose latent spaces.
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
In this paper, we take the advantage of previous pre-trained models (PTMs) and propose a novel Chinese Pre-trained Unbalanced Transformer (CPT).

Learning Object-Compositional Neural Radiance Field for Editable Scene Rendering
In this paper, we present a novel neural scene rendering system, which learns an object-compositional neural radiance field and produces realistic rendering with editing capability for a clustered and real-world scene.
DeepPanoContext: Panoramic 3D Scene Understanding with Holistic Scene Context Graph and Relation-based Optimization
Panorama images have a much larger field-of-view thus naturally encode enriched scene context information compared to standard perspective images, which however is not well exploited in the previous scene understanding methods.
MINERVAS: Massive INterior EnviRonments VirtuAl Synthesis
With the rapid development of data-driven techniques, data has played an essential role in various computer vision tasks.
Attention-guided Temporally Coherent Video Object Matting
Experimental results show that our method can generate high-quality alpha mattes for various videos featuring appearance change, occlusion, and fast motion.
VS-Net: Voting with Segmentation for Visual Localization
To address this problem, we propose a novel visual localization framework that establishes 2D-to-3D correspondences between the query image and the 3D map with a series of learnable scene-specific landmarks.

Animatable Neural Radiance Fields for Modeling Dynamic Human Bodies
Moreover, the learned blend weight fields can be combined with input skeletal motions to generate new deformation fields to animate the human model.
StereoPIFu: Depth Aware Clothed Human Digitization via Stereo Vision
In this paper, we propose StereoPIFu, which integrates the geometric constraints of stereo vision with implicit function representation of PIFu, to recover the 3D shape of the clothed human from a pair of low-cost rectified images.
NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video
We present a novel framework named NeuralRecon for real-time 3D scene reconstruction from a monocular video.
LoFTR: Detector-Free Local Feature Matching with Transformers
We present a novel method for local image feature matching.

Reconstructing 3D Human Pose by Watching Humans in the Mirror
In this paper, we introduce the new task of reconstructing 3D human pose from a single image in which we can see the person and the person's image through a mirror.

AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis
Generating high-fidelity talking head video by fitting with the input audio sequence is a challenging problem that receives considerable attentions recently.

Active Boundary Loss for Semantic Segmentation
This paper proposes a novel active boundary loss for semantic segmentation.
You Don't Only Look Once: Constructing Spatial-Temporal Memory for Integrated 3D Object Detection and Tracking
In this work, we propose a novel system for integrated 3D object detection and tracking, which uses a dynamic object occupancy map and previous object states as spatial-temporal memory to assist object detection in future frames.

Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
To this end, we propose Neural Body, a new human body representation which assumes that the learned neural representations at different frames share the same set of latent codes anchored to a deformable mesh, so that the observations across frames can be naturally integrated.

Location-aware Single Image Reflection Removal
It is beneficial to strong reflection detection and substantially improves the quality of reflection removal results.
Recurrent Multi-view Alignment Network for Unsupervised Surface Registration
Learning non-rigid registration in an end-to-end manner is challenging due to the inherent high degrees of freedom and the lack of labeled training data.

SelfVoxeLO: Self-supervised LiDAR Odometry with Voxel-based Deep Neural Networks
To suit our network to self-supervised learning, we design several novel loss functions that utilize the inherent properties of LiDAR point clouds.

SMAP: Single-Shot Multi-Person Absolute 3D Pose Estimation
Recovering multi-person 3D poses with absolute scales from a single RGB image is a challenging problem due to the inherent depth and scale ambiguity from a single view.
 Ranked #11 on
3D Multi-Person Pose Estimation (absolute)
on MuPoTS-3D
Ranked #11 on
3D Multi-Person Pose Estimation (absolute)
on MuPoTS-3D

Motion Capture from Internet Videos
Therefore, we propose to capture human motion by jointly analyzing these Internet videos instead of using single videos separately.
Mobile3DRecon: Real-time Monocular 3D Reconstruction on a Mobile Phone
The proposed mesh generation module incrementally fuses each estimated keyframe depth map to an online dense surface mesh, which is useful for achieving realistic AR effects such as occlusions and collisions.

Disp R-CNN: Stereo 3D Object Detection via Shape Prior Guided Instance Disparity Estimation
In this paper, we propose a novel system named Disp R-CNN for 3D object detection from stereo images.

 3D Object Detection From Stereo Images
3D Object Detection From Stereo Images
 Disparity Estimation
+2
Disparity Estimation
+2
BCNet: Learning Body and Cloth Shape from A Single Image
In this paper, we consider the problem to automatically reconstruct garment and body shapes from a single near-front view RGB image.
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose
In this paper, we address this problem by proposing a deep neural network model that takes an audio signal A of a source person and a very short video V of a target person as input, and outputs a synthesized high-quality talking face video with personalized head pose (making use of the visual information in V), expression and lip synchronization (by considering both A and V).


Deep Snake for Real-Time Instance Segmentation
Based on deep snake, we develop a two-stage pipeline for instance segmentation: initial contour proposal and contour deformation, which can handle errors in object localization.
 Ranked #2 on
Semantic Contour Prediction
on Sbd val
Ranked #2 on
Semantic Contour Prediction
on Sbd val
GIFT: Learning Transformation-Invariant Dense Visual Descriptors via Group CNNs
Instead of feature pooling, we use group convolutions to exploit underlying structures of the extracted features on the group, resulting in descriptors that are both discriminative and provably invariant to the group of transformations.
Depth Completion from Sparse LiDAR Data with Depth-Normal Constraints
Most of existing methods directly train a network to learn a mapping from sparse depth inputs to dense depth maps, which has difficulties in utilizing the 3D geometric constraints and handling the practical sensor noises.

Fast and Robust Multi-Person 3D Pose Estimation from Multiple Views
This paper addresses the problem of 3D pose estimation for multiple people in a few calibrated camera views.
 Ranked #12 on
3D Multi-Person Pose Estimation
on Campus
Ranked #12 on
3D Multi-Person Pose Estimation
on Campus
PVNet: Pixel-wise Voting Network for 6DoF Pose Estimation
We further create a Truncation LINEMOD dataset to validate the robustness of our approach against truncation.
 Ranked #2 on
6D Pose Estimation using RGB
on YCB-Video
(Mean AUC metric)
Ranked #2 on
6D Pose Estimation using RGB
on YCB-Video
(Mean AUC metric)

ICE-BA: Incremental, Consistent and Efficient Bundle Adjustment for Visual-Inertial SLAM
However, jointly using visual and inertial measurements to optimize SLAM objective functions is a problem of high computational complexity.
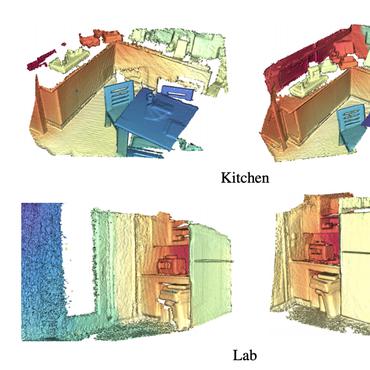
Robust Keyframe-based Dense SLAM with an RGB-D Camera
In this paper, we present RKD-SLAM, a robust keyframe-based dense SLAM approach for an RGB-D camera that can robustly handle fast motion and dense loop closure, and run without time limitation in a moderate size scene.
ENFT: Efficient Non-Consecutive Feature Tracking for Robust Structure-from-Motion
Our framework consists of steps of solving the feature `dropout' problem when indistinctive structures, noise or large image distortion exists, and of rapidly recognizing and joining common features located in different subsequences.
