Search Results for author:
Found 177 papers, 67 papers with code
基于中文信息与越南语句法指导的越南语事件检测(Vietnamese event detection based on Chinese information and Vietnamese syntax guidance)
“当前基于深度学习的事件检测模型都依赖足够数量的标注数据, 而标注数据的稀缺及事件类型歧义为越南语事件检测带来了极大的挑战。根据“表达相同观点但语言不同的句子通常有相同或相似的语义成分”这一多语言一致性特征, 本文提出了一种基于中文信息与越南语句法指导的越南语事件检测框架。首先通过共享编码器策略和交叉注意力网络将中文信息融入到越南语中, 然后使用图卷积网络融入越南语依存句法信息, 最后在中文事件类型指导下实现越南语事件检测。实验结果表明, 在中文信息和越南语句法的指导下越南语事件检测取得了较好的效果。”
Cross-Modal Conditioned Reconstruction for Language-guided Medical Image Segmentation
Recent developments underscore the potential of textual information in enhancing learning models for a deeper understanding of medical visual semantics.

Long and Short-Term Constraints Driven Safe Reinforcement Learning for Autonomous Driving
Reinforcement learning (RL) has been widely used in decision-making tasks, but it cannot guarantee the agent's safety in the training process due to the requirements of interaction with the environment, which seriously limits its industrial applications such as autonomous driving.

View-Consistent 3D Editing with Gaussian Splatting
The advent of 3D Gaussian Splatting (3DGS) has revolutionized 3D editing, offering efficient, high-fidelity rendering and enabling precise local manipulations.
Distributionally Generative Augmentation for Fair Facial Attribute Classification
This work proposes a novel, generation-based two-stage framework to train a fair FAC model on biased data without additional annotation.

SCHEMA: State CHangEs MAtter for Procedure Planning in Instructional Videos
We study the problem of procedure planning in instructional videos, which aims to make a goal-oriented sequence of action steps given partial visual state observations.

GenAD: Generative End-to-End Autonomous Driving
We then employ a variational autoencoder to learn the future trajectory distribution in a structural latent space for trajectory prior modeling.
Improving Data Augmentation for Robust Visual Question Answering with Effective Curriculum Learning
Compared to training on the entire augmented dataset, our ECL strategy can further enhance VQA models' performance with fewer training samples.


Turn-taking and Backchannel Prediction with Acoustic and Large Language Model Fusion
We propose an approach for continuous prediction of turn-taking and backchanneling locations in spoken dialogue by fusing a neural acoustic model with a large language model (LLM).

Boundary and Relation Distillation for Semantic Segmentation
Concurrently, the relation distillation transfers implicit relations from the teacher model to the student model using pixel-level self-relation as a bridge, ensuring that the student's mask has strong target region connectivity.
Two-pass Endpoint Detection for Speech Recognition
Endpoint (EP) detection is a key component of far-field speech recognition systems that assist the user through voice commands.

Multiperson Detection and Vital-Sign Sensing Empowered by Space-Time-Coding RISs
Passive human sensing using wireless signals has attracted increasing attention due to its superiorities of non-contact and robustness in various lighting conditions.
LingoQA: Video Question Answering for Autonomous Driving
To fill this gap, we introduce LingoQA, a benchmark specifically for autonomous driving Video QA.
Beneath the Surface: Unveiling Harmful Memes with Multimodal Reasoning Distilled from Large Language Models
The age of social media is rife with memes.
OpenStereo: A Comprehensive Benchmark for Stereo Matching and Strong Baseline
Based on OpenStereo, we conducted experiments and have achieved or surpassed the performance metrics reported in the original paper.

Automatic Detection of Alzheimer's Disease with Multi-Modal Fusion of Clinical MRI Scans
Notably, literature on the application of deep learning in the automatic detection of the disease has been proliferating.
DECap: Towards Generalized Explicit Caption Editing via Diffusion Mechanism
The denoising process involves the explicit predictions of edit operations and corresponding content words, refining reference captions through iterative step-wise editing.

Compositional Zero-shot Learning via Progressive Language-based Observations
Compositional zero-shot learning aims to recognize unseen state-object compositions by leveraging known primitives (state and object) during training.

Passive Human Sensing Enhanced by Reconfigurable Intelligent Surface: Opportunities and Challenges
Reconfigurable intelligent surfaces (RISs) have flexible and exceptional performance in manipulating electromagnetic waves and customizing wireless channels.
Video Referring Expression Comprehension via Transformer with Content-conditioned Query
Video Referring Expression Comprehension (REC) aims to localize a target object in videos based on the queried natural language.
Dataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond
Vision-language (VL) understanding tasks evaluate models' comprehension of complex visual scenes through multiple-choice questions.
V2X-AHD:Vehicle-to-Everything Cooperation Perception via Asymmetric Heterogenous Distillation Network
The V2X-AHD can effectively improve the accuracy of 3D object detection and reduce the number of network parameters, according to this study, which serves as a benchmark for cooperative perception.
 Ranked #2 on
3D Object Detection
on V2XSet
Ranked #2 on
3D Object Detection
on V2XSet

On the Cognition of Visual Question Answering Models and Human Intelligence: A Comparative Study
Visual Question Answering (VQA) is a challenging task that requires cross-modal understanding and reasoning of visual image and natural language question.
Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving
Large Language Models (LLMs) have shown promise in the autonomous driving sector, particularly in generalization and interpretability.
SortedAP: Rethinking evaluation metrics for instance segmentation
Designing metrics for evaluating instance segmentation revolves around comprehensively considering object detection and segmentation accuracy.

Semi-supervised Instance Segmentation with a Learned Shape Prior
To date, most instance segmentation approaches are based on supervised learning that requires a considerable amount of annotated object contours as training ground truth.
UniPT: Universal Parallel Tuning for Transfer Learning with Efficient Parameter and Memory
Parameter-efficient transfer learning (PETL), i. e., fine-tuning a small portion of parameters, is an effective strategy for adapting pre-trained models to downstream domains.
MEDOE: A Multi-Expert Decoder and Output Ensemble Framework for Long-tailed Semantic Segmentation
The proposed two-sage framework comprises a multi-expert decoder (MED) and a multi-expert output ensemble (MOE).

FusionPlanner: A Multi-task Motion Planner for Mining Trucks via Multi-sensor Fusion
Firstly, we propose a multi-task motion planning algorithm, called FusionPlanner, for autonomous mining trucks by the multi-sensor fusion method to adapt both lateral and longitudinal control tasks for unmanned transportation.

Compositional Feature Augmentation for Unbiased Scene Graph Generation
Specifically, we first decompose each relation triplet feature into two components: intrinsic feature and extrinsic feature, which correspond to the intrinsic characteristics and extrinsic contexts of a relation triplet, respectively.
A Survey on Open-Vocabulary Detection and Segmentation: Past, Present, and Future
By ``open-vocabulary'', we mean that the models can classify objects beyond pre-defined categories.
In Defense of Clip-based Video Relation Detection
While recent video-based methods utilizing video tubelets have shown promising results, we argue that the effective modeling of spatial and temporal context plays a more significant role than the choice between clip tubelets and video tubelets.

Machine Learning Study of the Extended Drug-target Interaction Network informed by Pain Related Voltage-Gated Sodium Channels
Pain is a significant global health issue, and the current treatment options for pain management have limitations in terms of effectiveness, side effects, and potential for addiction.
Improving Reference-based Distinctive Image Captioning with Contrastive Rewards
A recent DIC method proposes to generate distinctive captions by comparing the target image with a set of semantic-similar reference images, i. e., reference-based DIC (Ref-DIC).
Milestones in Autonomous Driving and Intelligent Vehicles Part II: Perception and Planning
Growing interest in autonomous driving (AD) and intelligent vehicles (IVs) is fueled by their promise for enhanced safety, efficiency, and economic benefits.
Enhanced Chart Understanding in Vision and Language Task via Cross-modal Pre-training on Plot Table Pairs
Building cross-model intelligence that can understand charts and communicate the salient information hidden behind them is an appealing challenge in the vision and language(V+L) community.

IdealGPT: Iteratively Decomposing Vision and Language Reasoning via Large Language Models
Specifically, IdealGPT utilizes an LLM to generate sub-questions, a VLM to provide corresponding sub-answers, and another LLM to reason to achieve the final answer.
Zero-shot Visual Relation Detection via Composite Visual Cues from Large Language Models
To dynamically fuse different cues, we further introduce a chain-of-thought method that prompts LLMs to generate reasonable weights for different visual cues.
TreePrompt: Learning to Compose Tree Prompts for Explainable Visual Grounding
In this paper, we argue that their poor interpretability is attributed to the holistic prompt generation and inference process.

Milestones in Autonomous Driving and Intelligent Vehicles Part I: Control, Computing System Design, Communication, HD Map, Testing, and Human Behaviors
Our work is divided into 3 independent articles and the first part is a Survey of Surveys (SoS) for total technologies of AD and IVs that involves the history, summarizes the milestones, and provides the perspectives, ethics, and future research directions.
Multi-Prompt with Depth Partitioned Cross-Modal Learning
In recent years, soft prompt learning methods have been proposed to fine-tune large-scale vision-language pre-trained models for various downstream tasks.
How Simulation Helps Autonomous Driving:A Survey of Sim2real, Digital Twins, and Parallel Intelligence
In general, a large scale of testing in simulation environment is conducted and then the learned driving knowledge is transferred to the real world, so how to adapt driving knowledge learned in simulation to reality becomes a critical issue.
Discrepancy-Guided Reconstruction Learning for Image Forgery Detection
In this paper, we propose a novel image forgery detection paradigm for boosting the model learning capacity on both forgery-sensitive and genuine compact visual patterns.
Milestones in Autonomous Driving and Intelligent Vehicles: Survey of Surveys
Interest in autonomous driving (AD) and intelligent vehicles (IVs) is growing at a rapid pace due to the convenience, safety, and economic benefits.
Cross-utterance ASR Rescoring with Graph-based Label Propagation
We propose a novel approach for ASR N-best hypothesis rescoring with graph-based label propagation by leveraging cross-utterance acoustic similarity.
Decomposed Prototype Learning for Few-Shot Scene Graph Generation
To this end, we propose a novel Decomposed Prototype Learning (DPL).
Motion Planning for Autonomous Driving: The State of the Art and Future Perspectives
Intelligent vehicles (IVs) have gained worldwide attention due to their increased convenience, safety advantages, and potential commercial value.
A Simple Baseline for Supervised Surround-view Depth Estimation
The former is achieved by the self-attention module within each view, while the latter is realized by the adjacent attention module, which computes the attention across multi-cameras to exchange the multi-scale representations across surround-view feature maps.

CrossFormer++: A Versatile Vision Transformer Hinging on Cross-scale Attention
On the one hand, CEL blends each token with multiple patches of different scales, providing the self-attention module itself with cross-scale features.

Learning Combinatorial Prompts for Universal Controllable Image Captioning
To this end, we propose a novel prompt-based framework for CIC by learning Combinatorial Prompts, dubbed as ComPro.
Compositional Prompt Tuning with Motion Cues for Open-vocabulary Video Relation Detection
Without bells and whistles, our RePro achieves a new state-of-the-art performance on two VidVRD benchmarks of not only the base training object and predicate categories, but also the unseen ones.
Iterative Proposal Refinement for Weakly-Supervised Video Grounding
Weakly-Supervised Video Grounding (WSVG) aims to localize events of interest in untrimmed videos with only video-level annotations.
TempCLR: Temporal Alignment Representation with Contrastive Learning
For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly.

MRTNet: Multi-Resolution Temporal Network for Video Sentence Grounding
In this work, we propose a novel multi-resolution temporal video sentence grounding network: MRTNet, which consists of a multi-modal feature encoder, a Multi-Resolution Temporal (MRT) module, and a predictor module.
Short term prediction of demand for ride hailing services: A deep learning approach
UberNet empploys a multivariate framework that utilises a number of temporal and spatial features that have been found in the literature to explain demand for ride-hailing services.
Line Drawing Guided Progressive Inpainting of Mural Damages
Mural image inpainting refers to repairing the damage or missing areas in a mural image to restore the visual appearance.

Sequential Transformer for End-to-End Person Search
Person Search aims to simultaneously localize and recognize a target person from realistic and uncropped gallery images.

Respecting Transfer Gap in Knowledge Distillation
The network response serves as additional supervision to formulate the machine domain, which uses the data collected from the human domain as a transfer set.
Weakly-Supervised Temporal Article Grounding
Specifically, given an article and a relevant video, WSAG aims to localize all ``groundable'' sentences to the video, and these sentences are possibly at different semantic scales.
Instance Segmentation of Dense and Overlapping Objects via Layering
Instance segmentation aims to delineate each individual object of interest in an image.
Transformer Meets Boundary Value Inverse Problems
A Transformer-based deep direct sampling method is proposed for electrical impedance tomography, a well-known severely ill-posed nonlinear boundary value inverse problem.
Cross-Skeleton Interaction Graph Aggregation Network for Representation Learning of Mouse Social Behaviour
Furthermore, we design a novel Interaction-Aware Transformer (IAT) to dynamically learn the graph-level representation of social behaviours and update the node-level representation, guided by our proposed interaction-aware self-attention mechanism.


Label Semantic Knowledge Distillation for Unbiased Scene Graph Generation
To this end, we propose a novel model-agnostic Label Semantic Knowledge Distillation (LS-KD) for unbiased SGG.
Integrating Object-aware and Interaction-aware Knowledge for Weakly Supervised Scene Graph Generation
However, we argue that most existing WSSGG works only focus on object-consistency, which means the grounded regions should have the same object category label as text entities.
Rethinking the Evaluation of Unbiased Scene Graph Generation
Current Scene Graph Generation (SGG) methods tend to predict frequent predicate categories and fail to recognize rare ones due to the severe imbalanced distribution of predicates.

A Transformer-based Generative Adversarial Network for Brain Tumor Segmentation
Our architecture consists of a generator and a discriminator, which are trained in min-max game progress.

NICEST: Noisy Label Correction and Training for Robust Scene Graph Generation
To this end, we propose a novel NoIsy label CorrEction and Sample Training strategy for SGG: NICEST.
Rethinking the Reference-based Distinctive Image Captioning
Unfortunately, reference images used by existing Ref-DIC works are easy to distinguish: these reference images only resemble the target image at scene-level and have few common objects, such that a Ref-DIC model can trivially generate distinctive captions even without considering the reference images.
Correspondence Matters for Video Referring Expression Comprehension
Extensive experiments demonstrate that our DCNet achieves state-of-the-art performance on both video and image REC benchmarks.
Explicit Image Caption Editing
Given an image and a reference caption, the image caption editing task aims to correct the misalignment errors and generate a refined caption.
Balancing the trade-off between cost and reliability for wireless sensor networks: a multi-objective optimized deployment method
In addition, this work fully considers the heterogeneity of SNs (i. e. differentiated sensing range and deployment cost) and three-dimensional (3-D) deployment scenarios.
Rethinking Data Augmentation for Robust Visual Question Answering
Unfortunately, to guarantee augmented samples have reasonable ground-truth answers, they manually design a set of heuristic rules for several question types, which extremely limits its generalization abilities.
Graph-based Multi-View Fusion and Local Adaptation: Mitigating Within-Household Confusability for Speaker Identification
Speaker identification (SID) in the household scenario (e. g., for smart speakers) is an important but challenging problem due to limited number of labeled (enrollment) utterances, confusable voices, and demographic imbalances.
Beyond Grounding: Extracting Fine-Grained Event Hierarchies Across Modalities
To support research on this task, we introduce the Multimodal Hierarchical Events (MultiHiEve) dataset.
The Devil is in the Labels: Noisy Label Correction for Robust Scene Graph Generation
Then, in Pos-NSD, we use a clustering-based algorithm to divide all positive samples into multiple sets, and treat the samples in the noisiest set as noisy positive samples.
The scope for AI-augmented interpretation of building blueprints in commercial and industrial property insurance
This report, commissioned by the WTW research network, investigates the use of AI in property risk assessment.
Rethinking Multi-Modal Alignment in Video Question Answering from Feature and Sample Perspectives
From the view of feature, we break down the video into trajectories and first leverage trajectory feature in VideoQA to enhance the alignment between two modalities.
Proximal Implicit ODE Solvers for Accelerating Learning Neural ODEs
Learning neural ODEs often requires solving very stiff ODE systems, primarily using explicit adaptive step size ODE solvers.
Learning 3D Semantics from Pose-Noisy 2D Images with Hierarchical Full Attention Network
This motivates us to conduct a "task transfer" paradigm so that 3D semantic segmentation benefits from aggregating 2D semantic cues, albeit pose noises are contained in 2D image observations.

Multi-Modal Few-Shot Object Detection with Meta-Learning-Based Cross-Modal Prompting
Our approach is motivated by the high-level conceptual similarity of (metric-based) meta-learning and prompt-based learning to learn generalizable few-shot and zero-shot object detection models respectively without fine-tuning.

Few-Shot Object Detection with Fully Cross-Transformer
Inspired by the recent work on vision transformers and vision-language transformers, we propose a novel Fully Cross-Transformer based model (FCT) for FSOD by incorporating cross-transformer into both the feature backbone and detection head.

SATr: Slice Attention with Transformer for Universal Lesion Detection
Universal Lesion Detection (ULD) in computed tomography plays an essential role in computer-aided diagnosis.
A Closer Look at Debiased Temporal Sentence Grounding in Videos: Dataset, Metric, and Approach
New benchmarking results indicate that our proposed evaluation protocols can better monitor the research progress.
openFEAT: Improving Speaker Identification by Open-set Few-shot Embedding Adaptation with Transformer
Household speaker identification with few enrollment utterances is an important yet challenging problem, especially when household members share similar voice characteristics and room acoustics.
AutoMine: An Unmanned Mine Dataset
The main contributions of the AutoMine dataset are as follows: 1. The first autonomous driving dataset for perception and localization in mine scenarios.
Rethinking the Two-Stage Framework for Grounded Situation Recognition
Since each verb is associated with a specific set of semantic roles, all existing GSR methods resort to a two-stage framework: predicting the verb in the first stage and detecting the semantic roles in the second stage.
 Ranked #3 on
Situation Recognition
on imSitu
Ranked #3 on
Situation Recognition
on imSitu

Classification-Then-Grounding: Reformulating Video Scene Graphs as Temporal Bipartite Graphs
To this end, we propose a new classification-then-grounding framework for VidSGG, which can avoid all the three overlooked drawbacks.
Unified Group Fairness on Federated Learning
We validate the advantages of the FMDA-M algorithm with various kinds of distribution shift settings in experiments, and the results show that FMDA-M algorithm outperforms the existing fair FL algorithms on unified group fairness.
High-throughput Phenotyping of Nematode Cysts
The beet cyst nematode (BCN) Heterodera schachtii is a plant pest responsible for crop loss on a global scale.
Counterfactual Samples Synthesizing and Training for Robust Visual Question Answering
Specifically, CSST is composed of two parts: Counterfactual Samples Synthesizing (CSS) and Counterfactual Samples Training (CST).
Natural Language Video Localization with Learnable Moment Proposals
Given an untrimmed video and a natural language query, Natural Language Video Localization (NLVL) aims to identify the video moment described by the query.
Image Deraining and Denoising Convolutional Neural Network ForAutonomous Driving
Perception plays an important role in reliable decision-making for autonomous vehicles.

On Pursuit of Designing Multi-modal Transformer for Video Grounding
Almost all existing video grounding methods fall into two frameworks: 1) Top-down model: It predefines a set of segment candidates and then conducts segment classification and regression.
Instance-wise or Class-wise? A Tale of Neighbor Shapley for Concept-based Explanation
Deep neural networks have demonstrated remarkable performance in many data-driven and prediction-oriented applications, and sometimes even perform better than humans.
Video Relation Detection via Tracklet based Visual Transformer
Video Visual Relation Detection (VidVRD), has received significant attention of our community over recent years.

Deep Motion Prior for Weakly-Supervised Temporal Action Localization
In this paper, we analyze that the motion cues behind the optical flow features are complementary informative.
 Optical Flow Estimation
Optical Flow Estimation
 Weakly-supervised Temporal Action Localization
+1
Weakly-supervised Temporal Action Localization
+1
FMMformer: Efficient and Flexible Transformer via Decomposed Near-field and Far-field Attention
For instance, FMMformers achieve an average classification accuracy of $60. 74\%$ over the five Long Range Arena tasks, which is significantly better than the standard transformer's average accuracy of $58. 70\%$.
CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention
On the one hand, CEL blends each embedding with multiple patches of different scales, providing the self-attention module itself with cross-scale features.
 Ranked #42 on
Semantic Segmentation
on ADE20K val
Ranked #42 on
Semantic Segmentation
on ADE20K val
Graph-based Label Propagation for Semi-Supervised Speaker Identification
We show in experiments on the VoxCeleb dataset that this approach makes effective use of unlabeled data and improves speaker identification accuracy compared to two state-of-the-art scoring methods as well as their semi-supervised variants based on pseudo-labels.
Shapley Counterfactual Credits for Multi-Agent Reinforcement Learning
Specifically, Shapley Value and its desired properties are leveraged in deep MARL to credit any combinations of agents, which grants us the capability to estimate the individual credit for each agent.
SDNet: mutil-branch for single image deraining using swin
The former implements the basic rain pattern feature extraction, while the latter fuses different features to further extract and process the image features.

Deep Learning for Weakly-Supervised Object Detection and Object Localization: A Survey
With the success of deep neural networks in object detection, both WSOD and WSOL have received unprecedented attention.
SimNet: Learning Reactive Self-driving Simulations from Real-world Observations
We train our system directly from 1, 000 hours of driving logs and measure both realism, reactivity of the simulation as the two key properties of the simulation.
What data do we need for training an AV motion planner?
If cheaper sensors could be used for collection instead, data availability would go up, which is crucial in a field where data volume requirements are large and availability is small.
VL-NMS: Breaking Proposal Bottlenecks in Two-Stage Visual-Language Matching
In this paper, we argue that these methods overlook an obvious \emph{mismatch} between the roles of proposals in the two stages: they generate proposals solely based on the detection confidence (i. e., query-agnostic), hoping that the proposals contain all instances mentioned in the text query (i. e., query-aware).
Textual Analysis of Communications in COVID-19 Infected Community on Social Media
During the COVID-19 pandemic, people started to discuss about pandemic-related topics on social media.
Conditional Training with Bounding Map for Universal Lesion Detection
Universal Lesion Detection (ULD) in computed tomography plays an essential role in computer-aided diagnosis.
 Ranked #3 on
Medical Object Detection
on DeepLesion
Ranked #3 on
Medical Object Detection
on DeepLesion
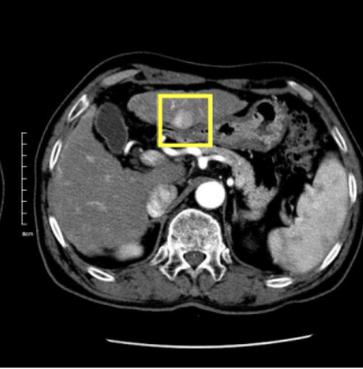
Human-like Controllable Image Captioning with Verb-specific Semantic Roles
However, we argue that almost all existing objective control signals have overlooked two indispensable characteristics of an ideal control signal: 1) Event-compatible: all visual contents referred to in a single sentence should be compatible with the described activity.
Boundary Proposal Network for Two-Stage Natural Language Video Localization
State-of-the-art NLVL methods are almost in one-stage fashion, which can be typically grouped into two categories: 1) anchor-based approach: it first pre-defines a series of video segment candidates (e. g., by sliding window), and then does classification for each candidate; 2) anchor-free approach: it directly predicts the probabilities for each video frame as a boundary or intermediate frame inside the positive segment.
A Closer Look at Temporal Sentence Grounding in Videos: Dataset and Metric
All the results demonstrate that the re-organized dataset splits and new metric can better monitor the progress in TSGV.
The electric dipole moment of the tau lepton revisited
We reconsider the issue of the search for a nonzero electric dipole form factor (EDM) $d_\tau(s)$ using optimal observables in $\tau^+\tau^-$ production by $e^+ e^-$ collisions in the center-of-mass energy range from the $\tau$-pair threshold to about $\sqrt{s} \sim 15$ GeV.
High Energy Physics - Phenomenology High Energy Physics - Experiment
Class balanced underwater object detection dataset generated by class-wise style augmentation
CWSA is a new kind of data augmentation technique which augments the training data for the minority classes by generating various colors, textures and contrasts for the minority classes.
Structured Context Enhancement Network for Mouse Pose Estimation
However, quantifying mouse behaviours from videos or images remains a challenging problem, where pose estimation plays an important role in describing mouse behaviours.

Trading Personalization for Accuracy: Data Debugging in Collaborative Filtering
Collaborative filtering has been widely used in recommender systems.


$ZH$ production in gluon fusion: two-loop amplitudes with full top quark mass dependence
We present results for the two-loop helicity amplitudes entering the NLO QCD corrections to the production of a Higgs boson in association with a $Z$-boson in gluon fusion.
High Energy Physics - Phenomenology
Lightweight Single-Image Super-Resolution Network with Attentive Auxiliary Feature Learning
In this paper, we develop a computation efficient yet accurate network based on the proposed attentive auxiliary features (A$^2$F) for SISR.

Multi-View Adaptive Fusion Network for 3D Object Detection
3D object detection based on LiDAR-camera fusion is becoming an emerging research theme for autonomous driving.
SWIPENET: Object detection in noisy underwater images
Moreover, inspired by the human education process that drives the learning from easy to hard concepts, we here propose the CMA training paradigm that first trains a clean detector which is free from the influence of noisy data.
Accelerate CNNs from Three Dimensions: A Comprehensive Pruning Framework
Specifically, it first casts the relationships between a certain model's accuracy and depth/width/resolution into a polynomial regression and then maximizes the polynomial to acquire the optimal values for the three dimensions.

AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results.
Ref-NMS: Breaking Proposal Bottlenecks in Two-Stage Referring Expression Grounding
The prevailing framework for solving referring expression grounding is based on a two-stage process: 1) detecting proposals with an object detector and 2) grounding the referent to one of the proposals.
Perceptual underwater image enhancement with deep learning and physical priors
Underwater image enhancement, as a pre-processing step to improve the accuracy of the following object detection task, has drawn considerable attention in the field of underwater navigation and ocean exploration.

Defining Digital Quadruplets in the Cyber-Physical-Social Space for Parallel Driving
The objectives of the three virtual digital vehicles are interacting, guiding, simulating and improving with the real vehicles.
Digital Quadruplets for Cyber-Physical-Social Systems based Parallel Driving: From Concept to Applications
The three virtual vehicles (descriptive, predictive, and prescriptive) dynamically interact with the real one in order to enhance the safety and performance of the real vehicle.
Deep Learning Based Brain Tumor Segmentation: A Survey
Brain tumor segmentation is one of the most challenging problems in medical image analysis.
Comparison of Different Methods for Time Sequence Prediction in Autonomous Vehicles
As a combination of various kinds of technologies, autonomous vehicles could complete a series of driving tasks by itself, such as perception, decision-making, planning, and control.
CANet: Context Aware Network for 3D Brain Glioma Segmentation
Automated segmentation of brain glioma plays an active role in diagnosis decision, progression monitoring and surgery planning.
Improving Pixel Embedding Learning through Intermediate Distance Regression Supervision for Instance Segmentation
A distance regression module is incorporated into our architecture to generate seeds for fast clustering.

CenterNet3D: An Anchor Free Object Detector for Point Cloud
However, because inherent sparsity of point clouds, 3D object center points are likely to be in empty space which makes it difficult to estimate accurate boundaries.
On Connections between Regularizations for Improving DNN Robustness
This paper analyzes regularization terms proposed recently for improving the adversarial robustness of deep neural networks (DNNs), from a theoretical point of view.
A Benchmark dataset for both underwater image enhancement and underwater object detection
To investigate how the underwater image enhancement methods influence the following underwater object detection tasks, in this paper, we provide a large-scale underwater object detection dataset with both bounding box annotations and high quality reference images, namely OUC dataset.
One Thousand and One Hours: Self-driving Motion Prediction Dataset
Motivated by the impact of large-scale datasets on ML systems we present the largest self-driving dataset for motion prediction to date, containing over 1, 000 hours of data.
Hierarchical Fashion Graph Network for Personalized Outfit Recommendation
Fashion outfit recommendation has attracted increasing attentions from online shopping services and fashion communities. Distinct from other scenarios (e. g., social networking or content sharing) which recommend a single item (e. g., a friend or picture) to a user, outfit recommendation predicts user preference on a set of well-matched fashion items. Hence, performing high-quality personalized outfit recommendation should satisfy two requirements -- 1) the nice compatibility of fashion items and 2) the consistence with user preference.
Underwater object detection using Invert Multi-Class Adaboost with deep learning
In addition, we propose a novel sample-weighted loss function which can model sample weights for SWIPENet, which uses a novel sample re-weighting algorithm, namely Invert Multi-Class Adaboost (IMA), to reduce the influence of noise on the proposed SWIPENet.
A CNN Framenwork Based on Line Annotations for Detecting Nematodes in Microscopic Images
The endpoints serve to untangle the skeletons from which segmentation masks are reconstructed by estimating the body width at each location along the skeleton.
In the Eyes of the Beholder: Analyzing Social Media Use of Neutral and Controversial Terms for COVID-19
To model the substantive difference of tweets with controversial terms and those with non-controversial terms, we apply topic modeling and LIWC-based sentiment analysis.

Instance Segmentation of Biomedical Images with an Object-aware Embedding Learned with Local Constraints
The network is trained to output embedding vectors of similar directions for pixels from the same object, while adjacent objects are orthogonal in the embedding space, which effectively avoids the fusion of objects in a crowd.
MixNet: Multi-modality Mix Network for Brain Segmentation
Automated brain structure segmentation is important to many clinical quantitative analysis and diagnoses.
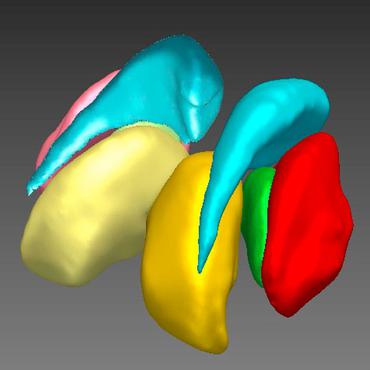
Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review
Autonomous vehicles were experiencing rapid development in the past few years.

Multi-Task Learning via Co-Attentive Sharing for Pedestrian Attribute Recognition
In this paper, we propose a novel Co-Attentive Sharing (CAS) module which extracts discriminative channels and spatial regions for more effective feature sharing in multi-task learning.

Location-Enabled IoT (LE-IoT): A Survey of Positioning Techniques, Error Sources, and Mitigation
Compared to the related surveys, this paper has a more comprehensive and state-of-the-art review on IoT localization methods, an original review on IoT localization error sources and mitigation, an original review on IoT localization performance evaluation, and a more comprehensive review of IoT localization applications, opportunities, and challenges.
Networking and Internet Architecture Signal Processing
Distinguish Confusing Law Articles for Legal Judgment Prediction
Legal Judgment Prediction (LJP) is the task of automatically predicting a law case's judgment results given a text describing its facts, which has excellent prospects in judicial assistance systems and convenient services for the public.
Counterfactual Samples Synthesizing for Robust Visual Question Answering
To reduce the language biases, several recent works introduce an auxiliary question-only model to regularize the training of targeted VQA model, and achieve dominating performance on VQA-CP.
 Ranked #1 on
Visual Question Answering (VQA)
on VQA-CP
(using extra training data)
Ranked #1 on
Visual Question Answering (VQA)
on VQA-CP
(using extra training data)
Cross-View Tracking for Multi-Human 3D Pose Estimation at over 100 FPS
To further verify the scalability of our method, we propose a new large-scale multi-human dataset with 12 to 28 camera views.
 Ranked #9 on
3D Multi-Person Pose Estimation
on Campus
Ranked #9 on
3D Multi-Person Pose Estimation
on Campus


Transductive Zero-Shot Hashing for Multilabel Image Retrieval
Given semantic annotations such as class labels and pairwise similarities of the training data, hashing methods can learn and generate effective and compact binary codes.
DEBUG: A Dense Bottom-Up Grounding Approach for Natural Language Video Localization
In this paper, we focus on natural language video localization: localizing (ie, grounding) a natural language description in a long and untrimmed video sequence.
Learning Lightweight Pedestrian Detector with Hierarchical Knowledge Distillation
It remains very challenging to build a pedestrian detection system for real world applications, which demand for both accuracy and speed.

Extreme Low Resolution Activity Recognition with Confident Spatial-Temporal Attention Transfer
Given the fact that one same activity may be represented by videos in both high resolution (HR) and extreme low resolution (eLR), it is worth studying to utilize the relevant HR data to improve the eLR activity recognition.
Exploiting Entity BIO Tag Embeddings and Multi-task Learning for Relation Extraction with Imbalanced Data
In practical scenario, relation extraction needs to first identify entity pairs that have relation and then assign a correct relation class.
Detection and Tracking of Multiple Mice Using Part Proposal Networks
The study of mouse social behaviours has been increasingly undertaken in neuroscience research.
Cost-sensitive Boosting Pruning Trees for depression detection on Twitter
Depression is one of the most common mental health disorders, and a large number of depressed people commit suicide each year.

MR-GNN: Multi-Resolution and Dual Graph Neural Network for Predicting Structured Entity Interactions
To resolve these problems, we present MR-GNN, an end-to-end graph neural network with the following features: i) it uses a multi-resolution based architecture to extract node features from different neighborhoods of each node, and, ii) it uses dual graph-state long short-term memory networks (L-STMs) to summarize local features of each graph and extracts the interaction features between pairwise graphs.
A prescription for projectors to compute helicity amplitudes in D dimensions
The usage of these D-dimensional polarized amplitude projectors results in helicity amplitudes that can be expressed solely in terms of external momenta, but different from those defined in the existing dimensional regularization schemes.
High Energy Physics - Phenomenology High Energy Physics - Theory
Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks
Specifically, information of each frame is abstracted by a CNN block, and the CNN features of multiple continuous frames, holding the property of time-series, are then fed into the RNN block for feature learning and lane prediction.

Monocular Outdoor Semantic Mapping with a Multi-task Network
First, with the correlation of underlying information between depth and semantic prediction, a novel multi-task Convolutional Neural Network (CNN) is designed for joint prediction.

Counterfactual Critic Multi-Agent Training for Scene Graph Generation
CMAT is a multi-agent policy gradient method that frames objects as cooperative agents, and then directly maximizes a graph-level metric as the reward.
Cross-Resolution Person Re-identification with Deep Antithetical Learning
One paradigm to deal with this problem is to use some complicated methods for mapping all images into an artificial image space, which however will disrupt the natural image distribution and requires heavy image preprocessing.
Real-time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification
Online multi-object tracking is a fundamental problem in time-critical video analysis applications.
![]() Ranked #4 on
Online Multi-Object Tracking
on MOT16
Ranked #4 on
Online Multi-Object Tracking
on MOT16
Large-Scale Person Re-Identification
Multi-Object Tracking
+2
End-to-end driving simulation via angle branched network
Imitation learning for end-to-end autonomous driving has drawn attention from academic communities.
Deep Dynamic Boosted Forest
Specically, we propose to measure the quality of each leaf node of every decision tree in the random forest to determine hard examples.
Self-Supervised Monocular Image Depth Learning and Confidence Estimation
Convolutional Neural Networks (CNNs) need large amounts of data with ground truth annotation, which is a challenging problem that has limited the development and fast deployment of CNNs for many computer vision tasks.

Context-Aware Mixed Reality: A Framework for Ubiquitous Interaction
Mixed Reality (MR) is a powerful interactive technology that yields new types of user experience.
Improved Deep Hashing with Soft Pairwise Similarity for Multi-label Image Retrieval
In this paper, a new deep hashing method is proposed for multi-label image retrieval by re-defining the pairwise similarity into an instance similarity, where the instance similarity is quantified into a percentage based on the normalized semantic labels.
Zero-Shot Visual Recognition using Semantics-Preserving Adversarial Embedding Networks
We propose a novel framework called Semantics-Preserving Adversarial Embedding Network (SP-AEN) for zero-shot visual recognition (ZSL), where test images and their classes are both unseen during training.

Improving Negative Sampling for Word Representation using Self-embedded Features
Although the word-popularity based negative sampler has shown superb performance in the skip-gram model, the theoretical motivation behind oversampling popular (non-observed) words as negative samples is still not well understood.
Maximum Principle Based Algorithms for Deep Learning
The continuous dynamical system approach to deep learning is explored in order to devise alternative frameworks for training algorithms.
Semantic Augmented Reality Environment with Material-Aware Physical Interactions
In Augmented Reality (AR) environment, realistic interactions between the virtual and real objects play a crucial role in user experience.
Real-time Geometry-Aware Augmented Reality in Minimally Invasive Surgery
The potential of Augmented Reality (AR) technology to assist minimally invasive surgeries (MIS) lies in its computational performance and accuracy in dealing with challenging MIS scenes.
Recent Developments and Future Challenges in Medical Mixed Reality
Mixed Reality (MR) is of increasing interest within technology-driven modern medicine but is not yet used in everyday practice.
Video Question Answering via Attribute-Augmented Attention Network Learning
Video Question Answering is a challenging problem in visual information retrieval, which provides the answer to the referenced video content according to the question.

Planecell: Representing the 3D Space with Planes
Reconstruction based on the stereo camera has received considerable attention recently, but two particular challenges still remain.
Augmented Reality for Depth Cues in Monocular Minimally Invasive Surgery
In vivo laparoscopic videos used in the tests have demonstrated the robustness and accuracy of our proposed framework on both camera tracking and surface reconstruction, illustrating the potential of our algorithm for depth augmentation and depth-corrected augmented reality in MIS with monocular endoscopes.
 Simultaneous Localization and Mapping
Surface Reconstruction
Simultaneous Localization and Mapping
Surface Reconstruction
Cascade one-vs-rest detection network for fine-grained recognition without part annotations
To bridge this gap, we introduce a cascaded structure to eliminate background and exploit a one-vs-rest loss to capture more minute variances among different subordinate categories.
SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
Existing visual attention models are generally spatial, i. e., the attention is modeled as spatial probabilities that re-weight the last conv-layer feature map of a CNN encoding an input image.

Who Leads the Clothing Fashion: Style, Color, or Texture? A Computational Study
Specifically, a classification-based model is proposed to quantify the influence of different visual stimuli, in which each visual stimulus's influence is quantified by its corresponding accuracy in fashion classification.
