Search Results for author:
Found 137 papers, 47 papers with code
Bounding-box Channels for Visual Relationship Detection
In this paper, we propose the bounding-box channels, a novel architecture capable of relating the semantic, spatial, and image features strongly.
Plug-and-Play Controller for Story Completion: A Pilot Study toward Emotion-aware Story Writing Assistance
Emotions are essential for storytelling and narrative generation, and as such, the relationship between stories and emotions has been extensively studied.
Learning to Evaluate Humor in Memes Based on the Incongruity Theory
Memes are a widely used means of communication on social media platforms, and are known for their ability to “go viral”.
Finding and Generating a Missing Part for Story Completion
We first conduct an experiment focusing on MPP, and our analysis shows that highly accurate predictions can be obtained when the missing part of a story is the beginning or the end.
Find n' Propagate: Open-Vocabulary 3D Object Detection in Urban Environments
In this work, we tackle the limitations of current LiDAR-based 3D object detection systems, which are hindered by a restricted class vocabulary and the high costs associated with annotating new object classes.

HyperVQ: MLR-based Vector Quantization in Hyperbolic Space
However, since the VQVAE is trained with a reconstruction objective, there is no constraint for the embeddings to be well disentangled, a crucial aspect for using them in discriminative tasks.

Symmetric Q-learning: Reducing Skewness of Bellman Error in Online Reinforcement Learning
In deep reinforcement learning, estimating the value function to evaluate the quality of states and actions is essential.

Robustifying a Policy in Multi-Agent RL with Diverse Cooperative Behaviors and Adversarial Style Sampling for Assistive Tasks
We demonstrate that policies trained with a popular deep RL method are vulnerable to changes in policies of other agents and that the proposed framework improves the robustness against such changes.
Advancing Large Multi-modal Models with Explicit Chain-of-Reasoning and Visual Question Generation
The increasing demand for intelligent systems capable of interpreting and reasoning about visual content requires the development of Large Multi-Modal Models (LMMs) that are not only accurate but also have explicit reasoning capabilities.

GPAvatar: Generalizable and Precise Head Avatar from Image(s)
Head avatar reconstruction, crucial for applications in virtual reality, online meetings, gaming, and film industries, has garnered substantial attention within the computer vision community.

Can Physician Judgment Enhance Model Trustworthiness? A Case Study on Predicting Pathological Lymph Nodes in Rectal Cancer
We hypothesize that superior attention maps should align with the information that physicians focus on, potentially reducing prediction uncertainty and increasing model reliability.
Aleth-NeRF: Illumination Adaptive NeRF with Concealing Field Assumption
The standard Neural Radiance Fields (NeRF) paradigm employs a viewer-centered methodology, entangling the aspects of illumination and material reflectance into emission solely from 3D points.
Combining inherent knowledge of vision-language models with unsupervised domain adaptation through self-knowledge distillation
In a first step, we generate the zero-shot predictions of the source and target dataset using the vision-language model.
 Ranked #1 on
Domain Adaptation
on Office-Home
Ranked #1 on
Domain Adaptation
on Office-Home
Fully Spiking Denoising Diffusion Implicit Models
Spiking neural networks (SNNs) have garnered considerable attention owing to their ability to run on neuromorphic devices with super-high speeds and remarkable energy efficiencies.


Gradual Source Domain Expansion for Unsupervised Domain Adaptation
Unsupervised domain adaptation (UDA) tries to overcome the need for a large labeled dataset by transferring knowledge from a source dataset, with lots of labeled data, to a target dataset, that has no labeled data.
 Ranked #5 on
Domain Adaptation
on Office-31
Ranked #5 on
Domain Adaptation
on Office-31
Expert Uncertainty and Severity Aware Chest X-Ray Classification by Multi-Relationship Graph Learning
In this paper, we re-extract disease labels from CXR reports to make them more realistic by considering disease severity and uncertainty in classification.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding.

Expert Knowledge-Aware Image Difference Graph Representation Learning for Difference-Aware Medical Visual Question Answering
Given a pair of main and reference images, this task attempts to answer several questions on both diseases and, more importantly, the differences between them.
Soft Curriculum for Learning Conditional GANs with Noisy-Labeled and Uncurated Unlabeled Data
Label-noise or curated unlabeled data is used to compensate for the assumption of clean labeled data in training the conditional generative adversarial network; however, satisfying such an extended assumption is occasionally laborious or impractical.

HiPerformer: Hierarchically Permutation-Equivariant Transformer for Time Series Forecasting
It is imperative to discern the relationships between multiple time series for accurate forecasting.

Domain Adaptive Multiple Instance Learning for Instance-level Prediction of Pathological Images
We conducted experiments on the pathological image dataset we created for this study and showed that the proposed method significantly improves the classification performance compared to existing methods.

Aleth-NeRF: Low-light Condition View Synthesis with Concealing Fields
Common capture low-light scenes are challenging for most computer vision techniques, including Neural Radiance Fields (NeRF).
Self-Supervised Learning for Group Equivariant Neural Networks
To ensure that training is consistent with the equivariance, we propose two concepts for self-supervised tasks: equivariant pretext labels and invariant contrastive loss.

Sketch-based Medical Image Retrieval
As a result, our SBMIR system enabled users to overcome previous challenges, including image retrieval based on fine-grained image characteristics, image retrieval without example images, and image retrieval for isolated samples.
Interpretable Medical Image Visual Question Answering via Multi-Modal Relationship Graph Learning
Medical visual question answering (VQA) aims to answer clinically relevant questions regarding input medical images.
Backprop Induced Feature Weighting for Adversarial Domain Adaptation with Iterative Label Distribution Alignment
Firstly, it lets the domain classifier focus on features that are important for the classification, and, secondly, it couples the classification and adversarial branch more closely.
Ranked #8 on
Domain Adaptation
on Office-31

Name Your Colour For the Task: Artificially Discover Colour Naming via Colour Quantisation Transformer
Besides, our colour quantisation method also offers an efficient quantisation method that effectively compresses the image storage while maintaining high performance in high-level recognition tasks such as classification and detection.
Learning by Asking Questions for Knowledge-based Novel Object Recognition
Our pipeline consists of two components: the Object Classifier, which performs knowledge-based object recognition, and the Question Generator, which generates knowledge-aware questions to acquire novel knowledge.

Grouped self-attention mechanism for a memory-efficient Transformer
Time-series data analysis is important because numerous real-world tasks such as forecasting weather, electricity consumption, and stock market involve predicting data that vary over time.

Memory Efficient Temporal & Visual Graph Model for Unsupervised Video Domain Adaptation
Existing video domain adaption (DA) methods need to store all temporal combinations of video frames or pair the source and target videos, which are memory cost expensive and can't scale up to long videos.
Exploring Resolution and Degradation Clues as Self-supervised Signal for Low Quality Object Detection
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in low quality images.
Deforming Radiance Fields with Cages
Recent advances in radiance fields enable photorealistic rendering of static or dynamic 3D scenes, but still do not support explicit deformation that is used for scene manipulation or animation.
SATTS: Speaker Attractor Text to Speech, Learning to Speak by Learning to Separate
The mapping of text to speech (TTS) is non-deterministic, letters may be pronounced differently based on context, or phonemes can vary depending on various physiological and stylistic factors like gender, age, accent, emotions, etc.

You Only Need 90K Parameters to Adapt Light: A Light Weight Transformer for Image Enhancement and Exposure Correction
Challenging illumination conditions (low-light, under-exposure and over-exposure) in the real world not only cast an unpleasant visual appearance but also taint the computer vision tasks.
 Ranked #2 on
Image Enhancement
on Exposure-Errors
Ranked #2 on
Image Enhancement
on Exposure-Errors

Non-rigid Point Cloud Registration with Neural Deformation Pyramid
Non-rigid point cloud registration is a key component in many computer vision and computer graphics applications.
Computational Storytelling and Emotions: A Survey
Storytelling has always been vital for human nature.
Multitask AET with Orthogonal Tangent Regularity for Dark Object Detection
To enhance object detection in a dark environment, we propose a novel multitask auto encoding transformation (MAET) model which is able to explore the intrinsic pattern behind illumination translation.
 Ranked #1 on
2D Object Detection
on ExDark
Ranked #1 on
2D Object Detection
on ExDark
Unsupervised Learning of Efficient Geometry-Aware Neural Articulated Representations
We propose an unsupervised method for 3D geometry-aware representation learning of articulated objects, in which no image-pose pairs or foreground masks are used for training.
Learning from Label Proportions with Instance-wise Consistency
Learning from Label Proportions (LLP) is a weakly supervised learning method that aims to perform instance classification from training data consisting of pairs of bags containing multiple instances and the class label proportions within the bags.
Revisiting Domain Generalized Stereo Matching Networks from a Feature Consistency Perspective
The stereo contrastive feature loss function explicitly constrains the consistency between learned features of matching pixel pairs which are observations of the same 3D points.

Enhancement of Novel View Synthesis Using Omnidirectional Image Completion
In this study, we present a method for synthesizing novel views from a single 360-degree RGB-D image based on the neural radiance field (NeRF) .
K-VQG: Knowledge-aware Visual Question Generation for Common-sense Acquisition
Visual Question Generation (VQG) is a task to generate questions from images.
ViNTER: Image Narrative Generation with Emotion-Arc-Aware Transformer
Image narrative generation is a task to create a story from an image with a subjective viewpoint.
Improving segmentation of calcified and non-calcified plaques on CCTA-CPR scans via masking of the artery wall
In this paper, we propose a novel methodology for segmenting calcified and non-calcified plaques in CCTA-CPR scans of coronary arteries.
RestoreDet: Degradation Equivariant Representation for Object Detection in Low Resolution Images
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in degraded images.
Watch It Move: Unsupervised Discovery of 3D Joints for Re-Posing of Articulated Objects
Rendering articulated objects while controlling their poses is critical to applications such as virtual reality or animation for movies.
Leveraging Human Selective Attention for Medical Image Analysis with Limited Training Data
Then we design a novel Auxiliary Attention Block (AAB) to allow information from SAN to be utilized by the backbone encoder to focus on selective areas.

Lepard: Learning partial point cloud matching in rigid and deformable scenes
We present Lepard, a Learning based approach for partial point cloud matching in rigid and deformable scenes.
 Ranked #1 on
Partial Point Cloud Matching
on 4DMatch
Ranked #1 on
Partial Point Cloud Matching
on 4DMatch
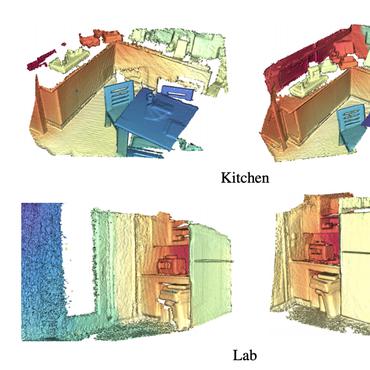

Unsupervised Pose-Aware Part Decomposition for 3D Articulated Objects
Articulated objects exist widely in the real world.

A Theoretical and Empirical Model of the Generalization Error under Time-Varying Learning Rate
In this study, we analyze the generalization bound for the time-varying case by applying PAC-Bayes and experimentally show that the theoretical functional form for the batch size and learning rate approximates the generalization error well for both cases.
Fully Spiking Variational Autoencoder
Spiking neural networks (SNNs) can be run on neuromorphic devices with ultra-high speed and ultra-low energy consumption because of their binary and event-driven nature.
Video Moment Retrieval with Text Query Considering Many-to-Many Correspondence Using Potentially Relevant Pair
In this paper, we propose a novel training method that takes advantage of potentially relevant pairs, which are detected based on linguistic analysis about text annotation.

Efficient training for future video generation based on hierarchical disentangled representation of latent variables
In this paper, we propose a novel method for generating future prediction videos with less memory usage than the conventional methods.
Neural Articulated Radiance Field
We present Neural Articulated Radiance Field (NARF), a novel deformable 3D representation for articulated objects learned from images.
Decomposing Normal and Abnormal Features of Medical Images into Discrete Latent Codes for Content-Based Image Retrieval
To support comparative diagnostic reading, content-based image retrieval (CBIR), which can selectively utilize normal and abnormal features in medical images as two separable semantic components, will be useful.
Estimating and Improving Fairness with Adversarial Learning
To tackle this issue, we propose an adversarial multi-task training strategy to simultaneously mitigate and detect bias in the deep learning-based medical image analysis system.
Goal-Oriented Gaze Estimation for Zero-Shot Learning
Therefore, we introduce a novel goal-oriented gaze estimation module (GEM) to improve the discriminative attribute localization based on the class-level attributes for ZSL.
Unsupervised Domain Adaptation via Minimized Joint Error
In this paper, we argue that the joint error is essential for the domain adaptation problem, in particular if the samples from different classes in source/target are closely aligned when matching the marginal distributions.
Decomposing Normal and Abnormal Features of Medical Images for Content-based Image Retrieval
Medical images can be decomposed into normal and abnormal features, which is considered as the compositionality.
Neural Star Domain as Primitive Representation
We show that NSD is a universal approximator of the star domain and is not only parsimonious and semantic but also an implicit and explicit shape representation.
Information Bottleneck Constrained Latent Bidirectional Embedding for Zero-Shot Learning
Though many ZSL methods rely on a direct mapping between the visual and the semantic space, the calibration deviation and hubness problem limit the generalization capability to unseen classes.

Neural Granular Sound Synthesis
In this setting the learned grain space is invertible, meaning that we can continuously synthesize sound when traversing its dimensions.

Learning Agile Locomotion via Adversarial Training
In contrast to prior works that used only one adversary, we find that training an ensemble of adversaries, each of which specializes in a different escaping strategy, is essential for the protagonist to master agility.
Point Cloud Based Reinforcement Learning for Sim-to-Real and Partial Observability in Visual Navigation
Reinforcement Learning (RL), among other learning-based methods, represents powerful tools to solve complex robotic tasks (e. g., actuation, manipulation, navigation, etc.
Vector-Quantized Timbre Representation
Although its definition is usually elusive, it can be seen from a signal processing viewpoint as all the spectral features that are perceived independently from pitch and loudness.
SplitFusion: Simultaneous Tracking and Mapping for Non-Rigid Scenes
We present SplitFusion, a novel dense RGB-D SLAM framework that simultaneously performs tracking and dense reconstruction for both rigid and non-rigid components of the scene.
Hyperbolic Neural Networks++
Hyperbolic spaces, which have the capacity to embed tree structures without distortion owing to their exponential volume growth, have recently been applied to machine learning to better capture the hierarchical nature of data.
Learning Global and Local Features of Normal Brain Anatomy for Unsupervised Abnormality Detection
In addition, we devise a metric to evaluate the anatomical fidelity of the reconstructed images and confirm that the overall detection performance is improved when the image reconstruction network achieves a higher score.

Learning to Optimize Non-Rigid Tracking
One of the widespread solutions for non-rigid tracking has a nested-loop structure: with Gauss-Newton to minimize a tracking objective in the outer loop, and Preconditioned Conjugate Gradient (PCG) to solve a sparse linear system in the inner loop.
Blur, Noise, and Compression Robust Generative Adversarial Networks
However, in contrast to NR-GAN, to address irreversible characteristics, we introduce masking architectures adjusting degradation strength values in a data-driven manner using bypasses before and after degradation.
Captioning Images with Novel Objects via Online Vocabulary Expansion
In this study, we introduce a low cost method for generating descriptions from images containing novel objects.


Coronary Wall Segmentation in CCTA Scans via a Hybrid Net with Contours Regularization
In this paper, we propose a novel boundary detection method for coronary arteries that focuses on the continuity and connectivity of the boundaries.
Spherical Image Generation from a Single Normal Field of View Image by Considering Scene Symmetry
We propose a method to generate spherical image from a single NFOV image, and control the degree of freedom of the generated regions using scene symmetry.
Noise Robust Generative Adversarial Networks
Therefore, we propose distribution and transformation constraints that encourage the noise generator to capture only the noise-specific components.

Unsupervised Keyword Extraction for Full-sentence VQA
In the majority of the existing Visual Question Answering (VQA) research, the answers consist of short, often single words, as per instructions given to the annotators during dataset construction.

Self-supervised Learning of 3D Objects from Natural Images
We present a method to learn single-view reconstruction of the 3D shape, pose, and texture of objects from categorized natural images in a self-supervised manner.

Domain Generalization Using a Mixture of Multiple Latent Domains
Conventional methods assume that the domain to which each sample belongs is known in training.
 Ranked #72 on
Domain Generalization
on PACS
Ranked #72 on
Domain Generalization
on PACS

Multi-Stage Pathological Image Classification using Semantic Segmentation
If we consider the relationship of neighboring patches and global features, we can improve the classification performance.

A General Upper Bound for Unsupervised Domain Adaptation
In this work, we present a novel upper bound of target error to address the problem for unsupervised domain adaptation.
Revisiting Fine-tuning for Few-shot Learning
With both tasks, we show that our method achieves higher accuracy than common few-shot learning algorithms.
Toward a Better Story End: Collecting Human Evaluation with Reasons
In this study, we undertake the task of story ending generation.
RGBD-GAN: Unsupervised 3D Representation Learning From Natural Image Datasets via RGBD Image Synthesis
The loss is simple yet effective for any type of image generator such as DCGAN and StyleGAN to be conditioned on camera parameters.
Rethinking Task and Metrics of Instance Segmentation on 3D Point Clouds
Certain existing studies have split input point clouds into small regions such as 1m x 1m; one reason for this is that models in the studies cannot consume a large number of points because of the large space complexity.


Measuring Numerical Common Sense: Is A Word Embedding Approach Effective?
To this end, we first used a crowdsourcing service to obtain sufficient data for a subjective agreement on numerical common sense.
Invariant Feature Coding using Tensor Product Representation
Based on this result, a novel feature model that explicitly consider group action is proposed for principal component analysis and k-means clustering, which are commonly used in most feature coding methods, and global feature functions.
Compact Approximation for Polynomial of Covariance Feature
Subsequently, we apply the proposed approximation to the polynomial corresponding to the matrix square root to obtain a compact approximation for the square root of the covariance feature.
Scalable Generative Models for Graphs with Graph Attention Mechanism
Graphs are ubiquitous real-world data structures, and generative models that approximate distributions over graphs and derive new samples from them have significant importance.
Improved Optical Flow for Gesture-based Human-robot Interaction
Gesture interaction is a natural way of communicating with a robot as an alternative to speech.

Interactive Video Retrieval with Dialog
We propose a system to retrieve videos by asking questions about the content of the videos and leveraging the user's responses to the questions.
Label-Noise Robust Multi-Domain Image-to-Image Translation
This problem is challenging in terms of scalability because it requires the learning of numerous mappings, the number of which increases proportional to the number of domains.

Long-Term Human Video Generation of Multiple Futures Using Poses
First, from an input human video, we generate sequences of future human poses (i. e., the image coordinates of their body-joints) via adversarial learning.

Image Generation From Small Datasets via Batch Statistics Adaptation
To reduce the amount of data required, we propose a new method for transferring prior knowledge of the pre-trained generator, which is trained with a large dataset, to a small dataset in a different domain.
End-to-End Learning Using Cycle Consistency for Image-to-Caption Transformations
So far, research to generate captions from images has been carried out from the viewpoint that a caption holds sufficient information for an image.
Pose Graph Optimization for Unsupervised Monocular Visual Odometry
In this paper, we propose to leverage graph optimization and loop closure detection to overcome limitations of unsupervised learning based monocular visual odometry.

TWINs: Two Weighted Inconsistency-reduced Networks for Partial Domain Adaptation
We utilize two classification networks to estimate the ratio of the target samples in each class with which a classification loss is weighted to adapt the classes present in the target domain.
Strong-Weak Distribution Alignment for Adaptive Object Detection
This motivates us to propose a novel method for detector adaptation based on strong local alignment and weak global alignment.
 Ranked #2 on
Unsupervised Domain Adaptation
on SIM10K to BDD100K
Ranked #2 on
Unsupervised Domain Adaptation
on SIM10K to BDD100K
Multichannel Semantic Segmentation with Unsupervised Domain Adaptation
The other is a multitask learning approach that uses depth images as outputs.
Learning to Explain with Complemental Examples
This paper addresses the generation of explanations with visual examples.
Conditional Video Generation Using Action-Appearance Captions
The results demonstrate that CFT-GAN is able to successfully generate videos containing the action and appearances indicated in the captions.

Multimodal Explanations by Predicting Counterfactuality in Videos
This study addresses generating counterfactual explanations with multimodal information.

Generating Easy-to-Understand Referring Expressions for Target Identifications
Moreover, we regard that sentences that are easily understood are those that are comprehended correctly and quickly by humans.
Class-Distinct and Class-Mutual Image Generation with GANs
To overcome this limitation, we address a novel problem called class-distinct and class-mutual image generation, in which the goal is to construct a generator that can capture between-class relationships and generate an image selectively conditioned on the class specificity.
Label-Noise Robust Generative Adversarial Networks
To remedy this, we propose a novel family of GANs called label-noise robust GANs (rGANs), which, by incorporating a noise transition model, can learn a clean label conditional generative distribution even when training labels are noisy.
Learning View Priors for Single-view 3D Reconstruction
The discriminator is trained to distinguish the reconstructed views of the observed viewpoints from those of the unobserved viewpoints.

Visual Question Generation for Class Acquisition of Unknown Objects
In this paper, we propose a method for generating questions about unknown objects in an image, as means to get information about classes that have not been learned.
Open Set Domain Adaptation by Backpropagation
Almost all of them are proposed for a closed-set scenario, where the source and the target domain completely share the class of their samples.
Customized Image Narrative Generation via Interactive Visual Question Generation and Answering
Image description task has been invariably examined in a static manner with qualitative presumptions held to be universally applicable, regardless of the scope or target of the description.
Viewpoint-aware Video Summarization
To satisfy these requirements (A)-(C) simultaneously, we proposed a novel video summarization method from multiple groups of videos.

MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes
We benchmarked our method by creating an RGB-Thermal dataset in which thermal and RGB images are combined.
 Ranked #5 on
Thermal Image Segmentation
on KP day-night
Ranked #5 on
Thermal Image Segmentation
on KP day-night

Maximum Classifier Discrepancy for Unsupervised Domain Adaptation
To solve these problems, we introduce a new approach that attempts to align distributions of source and target by utilizing the task-specific decision boundaries.
 Ranked #3 on
Domain Adaptation
on HMDBfull-to-UCF
Ranked #3 on
Domain Adaptation
on HMDBfull-to-UCF
 Image Classification
Image Classification
 Multi-Source Unsupervised Domain Adaptation
+2
Multi-Source Unsupervised Domain Adaptation
+2
Between-class Learning for Image Classification
Second, we propose a mixing method that treats the images as waveforms, which leads to a further improvement in performance.
Learning from Between-class Examples for Deep Sound Recognition
Deep learning methods have achieved high performance in sound recognition tasks.

Hierarchical Video Generation from Orthogonal Information: Optical Flow and Texture
FlowGAN generates optical flow, which contains only the edge and motion of the videos to be begerated.

Neural 3D Mesh Renderer
Using this renderer, we perform single-image 3D mesh reconstruction with silhouette image supervision and our system outperforms the existing voxel-based approach.
 Ranked #6 on
3D Object Reconstruction
on Data3D−R2N2
(Avg F1 metric)
Ranked #6 on
3D Object Reconstruction
on Data3D−R2N2
(Avg F1 metric)

Adversarial Dropout Regularization
However, a drawback of this approach is that the critic simply labels the generated features as in-domain or not, without considering the boundaries between classes.
![]() Ranked #2 on
Synthetic-to-Real Translation
on Syn2Real-C
Ranked #2 on
Synthetic-to-Real Translation
on Syn2Real-C
Melody Generation for Pop Music via Word Representation of Musical Properties
Automatic melody generation for pop music has been a long-time aspiration for both AI researchers and musicians.
Sound Multimedia Audio and Speech Processing
Spatio-temporal Person Retrieval via Natural Language Queries
In this paper, we address the problem of spatio-temporal person retrieval from multiple videos using a natural language query, in which we output a tube (i. e., a sequence of bounding boxes) which encloses the person described by the query.
Asymmetric Tri-training for Unsupervised Domain Adaptation
Deep-layered models trained on a large number of labeled samples boost the accuracy of many tasks.
 Ranked #5 on
Sentiment Analysis
on Multi-Domain Sentiment Dataset
Ranked #5 on
Sentiment Analysis
on Multi-Domain Sentiment Dataset

Development of JavaScript-based deep learning platform and application to distributed training
In the experiments, we demonstrate their practicality by training VGGNet in a distributed manner using web browsers as the client.
DeMIAN: Deep Modality Invariant Adversarial Network
To obtain the common representations under such a situation, we propose to make the distributions over different modalities similar in the learned representations, namely modality-invariant representations.
The Color of the Cat is Gray: 1 Million Full-Sentences Visual Question Answering (FSVQA)
Visual Question Answering (VQA) task has showcased a new stage of interaction between language and vision, two of the most pivotal components of artificial intelligence.
DualNet: Domain-Invariant Network for Visual Question Answering
Visual question answering (VQA) task not only bridges the gap between images and language, but also requires that specific contents within the image are understood as indicated by linguistic context of the question, in order to generate the accurate answers.
Kernel Approximation via Empirical Orthogonal Decomposition for Unsupervised Feature Learning
Our experiments show that the proposed method is better than the random features method and comparable with the Nystrom method in terms of the approximation error and classification accuracy.
Multi-Label Ranking From Positive and Unlabeled Data
Such a setting has been studied as a positive and unlabeled (PU) classification problem in a binary setting.
Beyond Caption To Narrative: Video Captioning With Multiple Sentences
Recent advances in image captioning task have led to increasing interests in video captioning task.
Improved Dense Trajectory with Cross Streams
This new descriptor is calculated by applying discriminative weights learned from one network to a convolutional layer of the other network.
 Ranked #10 on
Action Classification
on Toyota Smarthome dataset
Ranked #10 on
Action Classification
on Toyota Smarthome dataset
Dense Image Representation with Spatial Pyramid VLAD Coding of CNN for Locally Robust Captioning
The workflow of extracting features from images using convolutional neural networks (CNN) and generating captions with recurrent neural networks (RNN) has become a de-facto standard for image captioning task.
Common Subspace for Model and Similarity: Phrase Learning for Caption Generation From Images
In order to overcome the shortage of training samples, CoSMoS obtains a subspace in which (a) all feature vectors associated with the same phrase are mapped as mutually close, (b) classifiers for each phrase are learned, and (c) training samples are shared among co-occurring phrases.
Recognizing Activities of Daily Living with a Wrist-mounted Camera
We present a novel dataset and a novel algorithm for recognizing activities of daily living (ADL) from a first-person wearable camera.

Visual Language Modeling on CNN Image Representations
Additionally, a method to measure naturalness can be complementary to Convolutional Neural Network (CNN) based features, which are known to be insensitive to the naturalness of images.
Image Reconstruction from Bag-of-Visual-Words
The objective of this work is to reconstruct an original image from Bag-of-Visual-Words (BoVW).
Implementation of a Practical Distributed Calculation System with Browsers and JavaScript, and Application to Distributed Deep Learning
We have also developed a new JavaScript neural network framework called "Sukiyaki" that uses general purpose GPUs with web browsers.
MILJS : Brand New JavaScript Libraries for Matrix Calculation and Machine Learning
Our core library offering a matrix calculation is called Sushi, which exhibits far better performance than any other leading machine learning libraries written in JavaScript.
Three Guidelines of Online Learning for Large-Scale Visual Recognition
In this paper, we would like to evaluate online learning algorithms for large-scale visual recognition using state-of-the-art features which are preselected and held fixed.
Graphical Gaussian Vector for Image Categorization
This paper proposes a novel image representation called a Graphical Gaussian Vector, which is a counterpart of the codebook and local feature matching approaches.

