AdversarialQA
Introduced by Bartolo et al. in Beat the AI: Investigating Adversarial Human Annotation for Reading Comprehension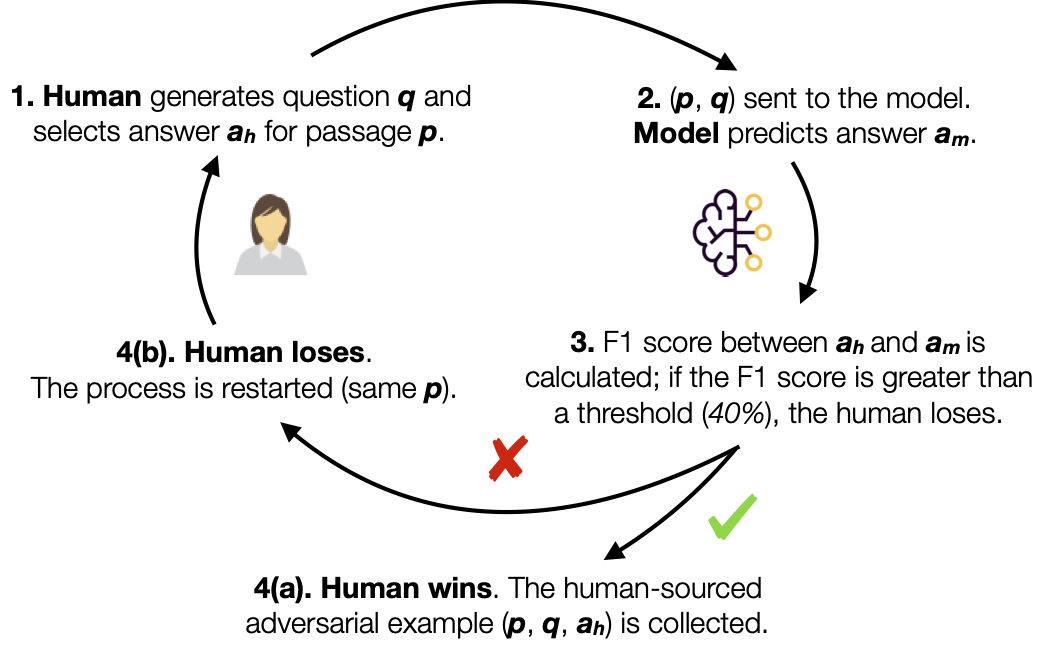
We have created three new Reading Comprehension datasets constructed using an adversarial model-in-the-loop.
We use three different models; BiDAF (Seo et al., 2016), BERTLarge (Devlin et al., 2018), and RoBERTaLarge (Liu et al., 2019) in the annotation loop and construct three datasets; D(BiDAF), D(BERT), and D(RoBERTa), each with 10,000 training examples, 1,000 validation, and 1,000 test examples.
The adversarial human annotation paradigm ensures that these datasets consist of questions that current state-of-the-art models (at least the ones used as adversaries in the annotation loop) find challenging. The three AdversarialQA round 1 datasets provide a training and evaluation resource for such methods.
Benchmarks
| Trend | Task | Dataset Variant | Best Model | Paper | Code |
|---|---|---|---|---|---|

|
adversarial_qa
|
mbartolo/roberta-large-synqa
|
|||

|
AdversarialQA
|
RoBERTa-Large
|
Papers
| Paper | Code | Results | Date | Stars |
|---|







