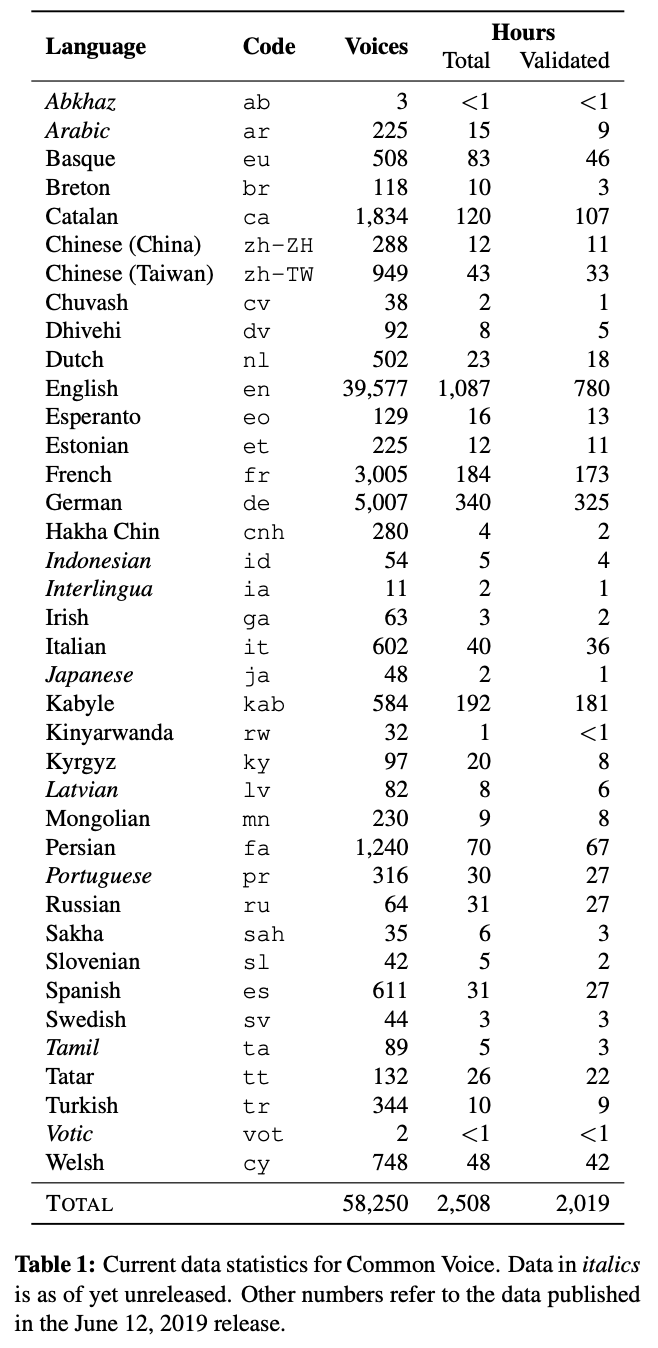
Common Voice is an audio dataset that consists of a unique MP3 and corresponding text file. There are 9,283 recorded hours in the dataset. The dataset also includes demographic metadata like age, sex, and accent. The dataset consists of 7,335 validated hours in 60 languages.
Benchmarks
| Trend | Task | Dataset Variant | Best Model | Paper | Code | TEST WER |
|---|---|---|---|---|---|---|

|
mozilla-foundation/common_voice_11_0
|
Whisper Small PL
|
|
|||

|
Common Voice German
|
wav2vec 2.0 XLS-R 1B + TEVR
|
3.64%
|
|||

|
Common Voice Turkish
|
mpoyraz/wav2vec2-xls-r-300m-cv6-turkish
|
8.83%
|
|||

|
Common Voice Portuguese
|
XLSR53 Wav2Vec2 Portuguese by Orlem Santos
|
10.74%
|
|||

|
Common Voice French
|
ConformerCTC-L
|
8.13%
|
|||

|
Common Voice Spanish
|
ConformerCTC-L
|
5.5%
|
|||

|
Common Voice 7.0 Finnish
|
wav2vec2-xlsr-1b-finnish-lm-v2
|
4.09%
|
|||

|
mozilla-foundation/common_voice_11_0 it
|
luigisaetta/whisper-medium-it
|
|
|||

|
Common Voice Indonesian
|
Wav2Vec2 Indonesian Javanese and Sundanese by Indonesian NLP
|
4.056%
|
|||

|
Common Voice 8.0 Dutch
|
xls-r-nl-v1-cv8-lm
|
3.93%
|
|||

|
Common Voice 7.0 Hindi
|
wav2vec2-xls-r-1b-hi-cv7
|
18.504%
|
|||

|
Mozilla Common Voice 10.0
|
stt_uk_citrinet_1024_gamma_0_25
|
4.65%
|
|||

|
Common Voice Swedish
|
Wav2vec 2.0 large VoxRex Swedish
|
6.472%
|
|||

|
Common Voice Vietnamese
|
Wav2vec2 Base Vietnamese 270h
|
9.66%
|
|||

|
Common Voice Hindi
|
Hindi Large
|
19.14%
|
|||

|
mozilla-foundation/common_voice_11_0 pt
|
Whisper Large Portuguese
|
|
|||

|
Common Voice Tamil
|
Wav2Vec2 Vakyansh Tamil Model by Harveen Chadha
|
53.64%
|
|||

|
Common Voice 7.0 Portuguese
|
bp_400h_xlsr2_300M
|
10.83%
|
|||

|
mozilla-foundation/common_voice_11_0 vi
|
openai/whisper-large-v2
|
|
|||

|
Common Voice English
|
parakeet-rnnt-1.1b
|
|
|||

|
Common Voice Estonian
|
xls-r-300m-et
|
12.52%
|
|||

|
Common Voice Arabic
|
XLSR Wav2Vec2 Arabic by Jonatas Grosman
|
39.59%
|
|||

|
Common Voice Japanese
|
wav2vec2-live-japanese
|
21.48%
|
|||

|
mozilla-foundation/common_voice_11_0 ja
|
Whisper Large V2 Japanese
|
|
|||

|
Common Voice Dutch
|
XLSR Wav2Vec2 Dutch by Jonatas Grosman
|
15.72%
|
|||

|
Common Voice 8.0 Sorbian, Upper
|
wav2vec2-large-xls-r-300m-hsb-v1
|
0.439%
|
|||

|
Common Voice 8.0 Slovenian
|
wav2vec2-large-xls-r-300m-sl-with-LM-v1
|
0.206%
|
|||

|
Common Voice 8.0 Portuguese
|
XLS-R Wav2Vec2 Portuguese by Jonatas Grosman
|
8.7%
|
|||

|
mozilla-foundation/common_voice_11_0 id
|
Whisper Medium Indonesian
|
|
|||

|
Common Voice Mongolian
|
XLSR Wav2Vec2 Mongolian V1 by Bayartsogt
|
34.64%
|
|||

|
Common Voice 8.0 Hindi
|
wav2vec2-large-xls-r-300m-hi-cv8
|
0.363%
|
|||

|
Common Voice Ukrainian
|
wav2vec2-xls-r-300m-uk
|
12.22%
|
|||

|
common_voice_11_0
|
firstcolab3
|
|
|||

|
Common Voice Russian
|
XLSR Wav2Vec2 Russian with Language Model by Ivan Bondarenko
|
12.115%
|
|||

|
Common Voice Odia
|
XLSR Wav2Vec2 Large 53 Odia by Gunjan Chhablani
|
52.64%
|
|||

|
Common Voice 8.0 French
|
XLS-R Wav2Vec2 French by Jonatas Grosman
|
16.85%
|
|||

|
Common Voice 8.0 Swedish
|
XLS-R-300M - Swedish - CV8
|
17.1%
|
|||

|
Common Voice Chinese (Hong Kong)
|
Whisper Large V2 Cantonese
|
|
|||

|
Mozilla Common Voice 9.0
|
stt_ca_conformer_transducer_large
|
3.85%
|
|||

|
Common Voice Irish
|
Wav2vec 2.0 large 300m XLS-R
|
25.94%
|
|||

|
mozilla-foundation/common_voice_11_0 es
|
openai/whisper-medium
|
|
|||

|
mozilla-foundation/common_voice_11_0 sv-SE
|
Whisper Large Swedish
|
|
|||

|
Common Voice Breton
|
XLSR Wav2Vec2 Breton by Cahya
|
41.71%
|
|||

|
Common Voice Basque
|
XLSR Wav2Vec2 Basque by Cahya
|
12.44%
|
|||

|
Common Voice Italian
|
Whisper
|
7.1%
|
|||

|
Common Voice Finnish
|
XLSR Wav2Vec2 Finnish by Aapo Tanskanen
|
32.379%
|
|||

|
Common Voice Frisian
|
wav2vec2-large-xls-r-1b-frisian
|
15.99%
|
|||

|
Common Voice 8.0 Estonian
|
xls-r-300m-et
|
13.384%
|
|||

|
Common Voice 8.0 Japanese
|
XLS-R-300-m
|
95.82%
|
|||

|
Common Voice 8.0 Marathi
|
wav2vec2-large-xls-r-300m-mr-v2
|
0.494%
|
|||

|
Common Voice Hungarian
|
XLSR Wav2Vec2 Hungarian by Jonatas Grosman
|
31.4%
|
|||

|
Common Voice Greek
|
XLSR Wav2Vec2 Greek by Jonatas Grosman
|
11.62%
|
|||

|
Common Voice Georgian
|
XLSR Wav2Vec2 Georgian by Mehrdad Farahani
|
43.86%
|
|||

|
Common Voice Luganda
|
Wav2Vec2 Luganda by Indonesian-NLP
|
7.53%
|
|||

|
Common Voice Persian
|
XLSR Wav2Vec2 Persian
|
10.36%
|
|||

|
Common Voice Punjabi
|
danurahul/wav2vec2-large-xlsr-pa-IN
|
54.86%
|
|||

|
Common Voice Sakha
|
Sakha XLSR Wav2Vec2 Large 53 by Anton Lozhkov
|
32.23%
|
|||

|
Common Voice Lithuanian
|
XLSR Wav2Vec2 Lithuanian by Mehrdad Farahani
|
34.66%
|
|||

|
Common Voice 7.0 Arabic
|
XLS-R-300M - Arabic
|
47.54%
|
|||

|
Common Voice 8.0 Catalan
|
wav2vec2-xls-r-300m-ca-lm
|
6.772%
|
|||

|
Common Voice 8.0 German
|
wav2vec2-xls-r-1b-5gram-german with LM by Florian Zimmermeister @A\\Ware
|
4.383%
|
|||

|
Common Voice 8.0 Czech
|
Czech comodoro Wav2Vec2 XLSR 300M 250h data
|
7.3%
|
|||

|
Common Voice 8.0 Spanish
|
XLS-R Wav2Vec2 Spanish by Jonatas Grosman
|
9.97%
|
|||

|
Common Voice 8.0 Maltese
|
wav2vec2-xls-r-300m-mt-o1
|
0.238%
|
|||

|
Common Voice 8.0 Basaa
|
wav2vec2-large-xls-r-300m-bas-v1
|
0.357%
|
|||

|
Common Voice 8.0 Tatar
|
wav2vec2-xls-r-300m-kk-n2
|
0.435%
|
|||

|
Common Voice 8.0 Assamese
|
wav2vec2-large-xls-r-300m-as-g1
|
0.654%
|
|||

|
Common Voice 8.0 Breton
|
wav2vec2-large-xls-r-300m-br-d2
|
0.498%
|
|||

|
Common Voice 8.0 Guarani
|
wav2vec2-large-xls-r-300m-gn-k1
|
0.712%
|
|||

|
mozilla-foundation/common_voice_11_0 tr
|
whisper-medium-mediaspeech-cv-tr
|
|
|||

|
mozilla-foundation/common_voice_11_0 fr
|
deepdml/whisper-medium-mix-fr
|
|
|||

|
Common Voice 8.0 Slovak
|
Slovak comodoro Wav2Vec2 XLSR 300M CV8
|
49.6%
|
|||

|
Common Voice 7.0 Italian
|
XLS-R-300m - Italian
|
17.17%
|
|||

|
Common Voice
|
MT-SLVR
|
|
|||

|
mozilla-foundation/common_voice_11_0 nl
|
Whisper Large v2 Dutch
|
|
|||

|
Common Voice 8.0 Russian
|
wav2vec2-large-xls-r-300m-kk-with-LM
|
0.435%
|
|||

|
Common Voice 8.0 Chinese (Hong Kong)
|
XLS-R-300M - Chinese_HongKong
|
|
|||

|
Common Voice Czech
|
Czech comodoro Wav2Vec2 XLSR 300M CV6.1
|
22.2%
|
|||

|
Common Voice 8.0 Hausa
|
Akashpb13/Hausa_xlsr
|
0.206%
|
|||

|
Mozilla Common Voice 11.0
|
stt_eo_conformer_transducer_large
|
4.0%
|
|||

|
Common Voice Sorbian, Upper
|
XLSR Wav2Vec2 Sorbian by Adam Montgomerie
|
41.74%
|
|||

|
Common Voice 8.0 Polish
|
XLS-R Wav2Vec2 Polish by Jonatas Grosman
|
11.01%
|
|||

|
Common Voice 8.0 Dhivehi
|
wav2vec2-xls-r-1b-dv
|
21.32%
|
|||

|
Common Voice Polish
|
XLSR Wav2Vec2 Polish by Jonatas Grosman
|
14.21%
|
|||

|
Common Voice 7.0 Latvian
|
wav2vec2-large-xls-r-1B-common_voice7-lv-ft
|
11.179%
|
|||

|
Common Voice Welsh
|
wav2vec2-xlsr-ft-en-cy
|
17.7%
|
|||

|
Common Voice 8.0 Armenian
|
wav2vec2-xls-r-1b-hy-cv
|
|
|||

|
Common Voice Chinese (China)
|
XLSR Wav2Vec2 Chinese
|
70.47%
|
|||

|
Common Voice Thai
|
XLSR Wav2Vec2 Large Thai by Sakares
|
41.263%
|
|||

|
Common Voice 8.0 Punjabi
|
wav2vec2-xls-r-300m-pa-IN-r5
|
0.419%
|
|||

|
mozilla-foundation/common_voice_11_0 hi
|
Whisper Large-v2 Hindi
|
|
|||

|
mozilla-foundation/common_voice_11_0 th
|
Whisper Small Thai
|
|
|||

|
Common Voice 7.0 Odia
|
Hindi Large
|
53.58%
|
|||

|
mozilla-foundation/common_voice_11_0 fi
|
Whisper medium Finnish CV
|
|
|||

|
mozilla-foundation/common_voice_11_0 el
|
whisper-sm-el-xs
|
|
|||

|
Common Voice 7.0 Swedish
|
XLS-R-300M - Swedish - CV7 - v2
|
15.99%
|
|||

|
Common Voice Assamese
|
Anurag Singh XLSR Wav2Vec2 Large 53 Assamese
|
69.63%
|
|||

|
mozilla-foundation/common_voice_11_0 fy-NL
|
Whisper Small Western Frisian
|
|
|||

|
Common Voice 8.0 Odia
|
wav2vec2-large-xls-r-300m-or-d5
|
0.579%
|
|||

|
Common Voice 8.0 Bulgarian
|
wav2vec2-large-xls-r-300m-bg-d2
|
0.288%
|
|||

|
Common Voice Esperanto
|
Wav2Vec2 Large 53 Esperanto by Gunjan Chhablani
|
10.13%
|
|||

|
Common Voice 8.0 Urdu
|
wav2vec2-large-xls-r-300m-Urdu
|
39.89%
|
|||

|
Common Voice Kyrgyz
|
Kyrgyz XLSR Wav2Vec2 Large 53 by Anton Lozhkov
|
31.88%
|
|||

|
Common Voice 7.0 Vietnamese
|
xls-asr-vi-40h-1B
|
|
|||

|
Mozilla Common Voice 8.0
|
stt_en_conformer_ctc_large
|
9.48%
|
|||

|
mozilla-foundation/common_voice_13_0 th
|
Whisper Medium Thai Combined V4 - biodatlab
|
|
|||

|
MCV 7.0
|
stt_fr_conformer_ctc_large
|
9.63%
|
|||

|
Common Voice 7.0 Spanish
|
xls-r-spanish-test
|
13.89%
|
|||

|
Common Voice 7.0 German
|
Wav2Vec2-Large-XLSR-53-German-GPT2
|
10.02%
|
|||

|
Common Voice Romanian
|
Romanian XLSR Wav2Vec2 Large 53 by Anton Lozhkov
|
24.84%
|
|||

|
Common Voice 7.0 Abkhaz
|
wav2vec2-large-xls-r-300m-ab-CV7
|
0.529%
|
|||

|
Common Voice 8.0 Irish
|
wav2vec2-large-xls-r-1b-Irish-Abid
|
|
|||

|
Common Voice Romansh Sursilvan
|
Wav2Vec2 Large 53 Romansh Sursilvan by Gunjan Chhablani
|
25.16%
|
|||

|
Common Voice Chuvash
|
Chuvash XLSR Wav2Vec2 Large 53 by Anton Lozhkov
|
40.01%
|
|||

|
Common Voice 8.0 Georgian
|
sammy786/wav2vec2-xlsr-czech
|
23.9%
|
|||

|
Common Voice 8.0 Italian
|
XLS-R Wav2Vec2 Italian by radiogroup crits
|
9.04%
|
|||

|
Common Voice 7.0 Irish
|
wav2vec-cv7-1b-ir
|
39.1%
|
|||

|
Common Voice 7.0 Romanian
|
XLS-R-300M - Romanian
|
14.194%
|
|||

|
Common Voice 7.0 Slovenian
|
XLS-R-300M - Slovenian
|
18.97%
|
|||

|
Common Voice 8.0 Indonesian
|
wav2vec2-large-xls-r-1b-Indonesian
|
45.51%
|
|||

|
Common Voice 7.0 Turkish
|
mpoyraz/wav2vec2-xls-r-300m-cv7-turkish
|
8.62%
|
|||

|
Common Voice Interlingua
|
Anurag Singh XLSR Wav2Vec2 Large 53 Interlingua
|
22.08%
|
|||

|
Common Voice 7.0 Indonesian
|
Wav2Vec2 Indonesian Javanese and Sundanese by Indonesian NLP
|
4.492%
|
|||

|
Common Voice 8.0 Ukrainian
|
wav2vec2-xls-r-1b-hy-cv
|
|
|||

|
Common Voice 8.0 Mongolian
|
sammy786/wav2vec2-xlsr-mongolian
|
32.63%
|
|||

|
Mozilla Common Voice 11.0 (Test)
|
wav2vec2-large-xlsr-53-maltese-64h
|
|
|||

|
Mozilla Common Voice 11.0 (Dev)
|
wav2vec2-large-xlsr-53-maltese-64h
|
|
|||

|
Common Voice 8.0 Abkhaz
|
XLS-R-300M - Abkhaz
|
27.6%
|
|||

|
Common Voice 8.0 Kyrgyz
|
sammy786/wav2vec2-xlsr-kyrgyz
|
25.24%
|
|||

|
Common Voice 8.0 Sakha
|
sammy786/wav2vec2-xlsr-sakha
|
36.15%
|
|||

|
Common Voice 7.0 Japanese
|
wav2vec2-xls-r-1b
|
|
|||

|
Common Voice 8.0 Interlingua
|
sammy786/wav2vec2-xlsr-interlingua
|
16.81%
|
|||

|
Common Voice 8.0 Romansh Sursilvan
|
wav2vec2-xls-r-300m-rm-sursilv-d11
|
0.241%
|
|||

|
Common Voice 7.0 Chinese (Hong Kong)
|
Wav2Vec2 XLS-R 300M Cantonese
|
|
|||

|
Common Voice 8.0 Romansh Vallader
|
wav2vec2-xls-r-300m-rm-vallader-d1
|
0.265%
|
|||

|
Common Voice Tatar
|
Tatar XLSR Wav2Vec2 Large 53 by Anton Lozhkov
|
26.76%
|
|||

|
Common Voice 8.0 Vietnamese
|
xls-asr-vi-40h-1B
|
|
|||

|
Common Voice 8.0 Santali (Ol Chiki)
|
wav2vec2-large-xls-r-300m-sat-final
|
0.349%
|
|||

|
Common Voice 8.0 Erzya
|
wav2vec2-large-xls-r-300m-myv-v1
|
0.6%
|
|||

|
Common Voice 8.0 Serbian
|
wav2vec2-large-xls-r-300m-sr-v4
|
0.303%
|
|||

|
Common Voice 8.0 Galician
|
wav2vec2-xls-r-300m-gl-CV8
|
22.94%
|
|||

|
Common Voice 7.0 Galician
|
Wav2Vec2-Large-XLSR-53-Galician-With-LM
|
22.12%
|
|||

|
Common Voice 9.0 Finnish
|
wav2vec2-base-fi-voxpopuli-v2-finetuned
|
5.93%
|
|||

|
Mozilla Common Voice 7.0
|
stt_en_conformer_transducer_xlarge
|
5.13%
|
|||

|
Common Voice 9.0 French
|
Fine-tuned Wav2Vec2 XLS-R 1B model for ASR in French
|
12.72%
|
|||

|
common-voice-7-0-6
|
stt_es_conformer_transducer_large
|
5.2%
|
|||

|
common-voice-11-0
|
stt_it_conformer_ctc_large
|
5.92%
|
|||

|
Mozilla Common Voice 10.0
|
stt_ru_conformer_transducer_large
|
|
|||

|
Mozilla Common Voice 10.0
|
stt_ru_conformer_transducer_large
|
3.96%
|
|||

|
Mozilla Common Voice 10.0 (Test)
|
wav2vec2-large-xlsr-53-spanish-ep5-944h
|
|
|||

|
Mozilla Common Voice 10.0 (Dev)
|
wav2vec2-large-xlsr-53-spanish-ep5-944h
|
|
|||

|
Common Voice Maltese
|
XLSR Wav2Vec2 Maltese by Akash PB
|
29.42%
|
|||

|
mozilla-foundation/common_voice_11_0 tt
|
Whisper Small Tatar - Kirill Milintsevich
|
|
|||

|
Common Voice Slovenian
|
Slovenian XLSR Wav2Vec2 Large 53 by Anton Lozhkov
|
36.04%
|
|||

|
mozilla-foundation/common_voice_11_0 pa-IN
|
Whisper Large-v2 Punjabi
|
|
|||

|
Common Voice Dhivehi
|
Shahu Kareem XLSR Wav2Vec2 Large 53 Dhivehi
|
32.85%
|
|||

|
mozilla-foundation/common_voice_11_0 mr
|
Whisper Large-v2 Marathi
|
|
|||

|
mozilla-foundation/common_voice_11_0 as
|
Whisper Large-v2 Assamese
|
|
|||

|
mozilla-foundation/common_voice_11_0 zh-TW
|
Whisper Small Traditional Chinese
|
|
|||

|
Common Voice Latvian
|
Latvian XLSR Wav2Vec2 Large 53 by Anton Lozhkov
|
26.89%
|
|||

|
mozilla-foundation/common_voice_11_0 ka
|
Whisper Large-v2 Georgian
|
|
|||

|
mozilla-foundation/common_voice_11_0 cy
|
Whisper Small Welsh
|
|
|||

|
mozilla-foundation/common_voice_11_0 be
|
Whisper Small Belarusian
|
|
|||

|
mozilla-foundation/common_voice_11_0 cs
|
Whisper Large-v2 Czech CV11
|
|
|||

|
mozilla-foundation/common_voice_11_0 ca
|
openai/whisper-medium
|
|
|||

|
Common Voice vi
|
wav2vec2-base-vietnamese-160h
|
10.78
|
|||

|
Common Voice 7.0 Bashkir
|
wav2vec2-large-xls-r-300m-bashkir-cv7_opt
|
0.044%
|
|||

|
Common Voice
|
ConformerXXL-P + Downstream NST
|
7.7%
|
|||

|
Common Voice 7.0 Assamese
|
wav2vec2-large-xls-r-300m-as
|
56.995%
|
|||

|
Common Voice 7.0 Urdu
|
wav2vec2-60-urdu
|
59.1%
|
|||

|
Common Voice 7.0 Ukrainian
|
wav2vec2-xls-r-300m-uk-with-lm
|
26.47%
|
|||

|
Common Voice Kinyarwanda
|
XLSR Wav2Vec2 Large Kinyarwanda with apostrophes
|
39.92%
|
|||

|
Common Voice 8.0 Kurmanji Kurdish
|
Akashpb13/Galician_xlsr
|
0.113%
|
|||

|
Common Voice 7.0 Chinese (China)
|
wav2vec2-xls-r-300m-zh-CN
|
80.0%
|
|||

|
mozilla-foundation/common_voice_11_0 ur
|
Whisper Small Urdu
|
|
|||

|
Common Voice 7.0 Basque
|
wav2vec2-large-xls-r-300m-basque
|
51.89%
|
|||

|
Common Voice Galician
|
wav2vec2-xls-r-300m-gl-CV8
|
0.208%
|
|||

|
Common Voice 8.0 Votic
|
wav2vec2-large-xls-r-300m-vot-final-a2
|
0.833%
|
|||

|
Common Voice 7.0 Luganda
|
Wav2Vec2 Luganda by Indonesian-NLP
|
13.844%
|
|||

|
Common Voice 7.0 Votic
|
wav2vec2-large-xls-r-300m-hi-d3
|
0.42%
|
|||

|
mozilla-foundation/common_voice_11_0 bn
|
Whisper Small Bengali
|
|
|||

|
mozilla-foundation/common_voice_11_0 fa
|
Whisper Small Persian
|
|
|||

|
Common Voice 8.0 Kazakh
|
wav2vec2-large-xls-r-300m-kk-with-LM
|
41.7%
|
|||

|
Common Voice 7.0 Guarani
|
wav2vec2-xls-r-gn-cv7
|
62.65%
|
|||

|
Common Voice 8.0 Belarusian
|
wav2vec2
|
18.7%
|
|||

|
Common Voice 9.0 Urdu
|
XLS-R-300M - Urdu
|
23.75%
|
|||

|
mozilla-foundation/common_voice_11_0 sl
|
Whisper Small Slovenian
|
|
|||

|
Common Voice 9.0 Marathi
|
XLS-R-300M - Marathi
|
23.841%
|
|||

|
Common Voice 9.0 Odia
|
XLS-R-300M - Odia
|
44.343%
|
|||

|
Common Voice 9.0 Hindi
|
XLS-R-300M - Hindi
|
21.145%
|
|||

|
mozilla-foundation/common_voice_11_0 kab
|
Whisper Small Georgian
|
|
|||

|
Mozilla Common Voice 8.0
|
stt_uk_citrinet_1024_gamma_0_25
|
5.02%
|
|||

|
Common Voice 9.0 Swedish
|
XLS-R-300M - Swedish
|
7.72%
|
|||

|
Common Voice 9.0 German
|
wav2vec2-large-xlsr-53-german-cv9
|
9.481%
|
|||

|
Common Voice 7
|
stt_de_conformer_ctc_large
|
6.68%
|
|||

|
Common Voice 7.0 Basaa
|
XLS-R-300M - Basaa
|
104.08%
|
|||

|
mozilla-foundation/common_voice_11_0 de
|
Whisper Small German
|
|
|||

|
common-voice-7-0
|
stt_de_conformer_transducer_large
|
4.93%
|
|||

|
CommonVoice (clean)
|
wav2vec2-base-960h-phoneme-reco-dutch
|
|
|||

|
mozilla-foundation/common_voice_9_0
|
Whisper Tiny PT
|
|
|||

|
mozilla-foundation/common_voice_11_0 ta
|
Whisper Small Tamil
|
|
|||

|
mozilla-foundation/common_voice_11_0 ru
|
Whisper Small Russian
|
|
|||

|
CommonVoice 7.0 (Spanish)
|
asr-wav2vec2-commonvoice-es
|
7.68%
|
|||

|
Common Voice 7.0 Thai
|
XLS-R-53 - Thai
|
0.952%
|
|||

|
mozilla-foundation/common_voice_11_0 ml
|
Whisper Large-v2 Malayalam
|
|
|||

|
Common Voice 8.0 Latvian
|
XLS-R-300M - Latvian
|
9.633%
|
|||

|
Common Voice 8.0 Central Kurdish
|
Akashpb13/Central_kurdish_xlsr
|
0.368%
|
|||

|
Common Voice Romansh Vallader
|
Anurag Singh XLSR Wav2Vec2 Large 53 Romansh Vallader
|
32.89%
|
|||

|
Common Voice 8.0 Hungarian
|
Akashpb13/xlsr_hungarian_new
|
0.285%
|
|||

|
Common Voice 7.0 Breton
|
XLS-R-300M - Breton
|
107.955%
|
|||

|
mozilla-foundation/common_voice_11_0 ba
|
Whisper Small Bashkir
|
|
|||

|
Common Voice 7.0 Romansh Sursilvan
|
XLS-R-300M - Romansh Sursilvan
|
19.816%
|
|||

|
Common Voice 7.0 Sakha
|
XLS-R-300M - Sakha
|
44.196%
|
|||

|
Common Voice 7.0 Slovak
|
XLS-R-300M - Slovak
|
24.852%
|
|||

|
Common Voice 8.0 Swahili
|
Akashpb13/Swahili_xlsr
|
0.118%
|
|||

|
Common Voice Chinese (Taiwan)
|
XLSR Wav2Vec2 Taiwanese Mandarin
|
|
|||

|
Common Voice 7.0 Uyghur
|
XLS-R-300M Uyghur CV7
|
25.845%
|
|||

|
Common Voice 8.0 Uyghur
|
XLS-R-300M Uyghur CV8
|
30.5%
|
|||

|
Common Voice 7.0 Russian
|
Russian Wav2Vec2 XLS-R 300m
|
27.81%
|
|||

|
Common Voice 7.0 Romansh Vallader
|
XLS-R-300M - Romansh Vallader
|
31.689%
|
|||

|
COMMON_VOICE - VI
|
wav2vec2-common_voice-vi
|
|
|||

|
Common Voice 8.0 Finnish
|
sammy786/wav2vec2-xlsr-finnish
|
13.72%
|
|||

|
Common Voice 7.0 Maltese
|
XLS-R-300M - Maltese
|
23.503%
|
|||

|
Common Voice Hakha Chin
|
Wav2Vec2 Large 53 Hakha Chin by Gunjan Chhablani
|
31.38%
|
|||

|
Common Voice 7.0 Lithuanian
|
XLS-R-300M - Lithuanian
|
24.859%
|
|||

|
Common Voice 7.0 Welsh
|
XLS-R-300M - Welsh
|
31.003%
|
|||

|
mozilla-foundation/common_voice_11_0 zh-CN
|
Whisper Small zh-CN - Alvin
|
|
|||

|
Common Voice 7.0 Mongolian
|
XLS-R-300M - Mongolian
|
44.709%
|
|||

|
ERR2020, Common Voice 11.0, FLEURS
|
Whisper Medium et
|
|
|||

|
CommonVoice Corpus 10.0/ (German)
|
asr-wav2vec2-commonvoice-de
|
9.54%
|
|||

|
Common Voice 8.0 Romanian
|
wav2vec2-ro-300m_01
|
|
|||

|
Common Voice 7.0 Kurmanji Kurdish
|
XLS-R-300M - Kurmanji Kurdish
|
102.308%
|
|||

|
Common Voice 8.0 Lithuanian
|
sammy786/wav2vec2-xlsr-lithuanian
|
14.67%
|
|||

|
Common Voice 7.0 Tatar
|
XLS-R-300M - Tatar
|
24.392%
|
|||

|
Common Voice 7.0 Chuvash
|
XLS-R-300M - Chuvash
|
60.31%
|
|||

|
Common Voice 8.0 Bashkir
|
sammy786/wav2vec2-xlsr-bashkir
|
11.32%
|
|||

|
Common Voice 7.0 Punjabi
|
XLS-R-300M - Punjabi
|
45.611%
|
|||

|
Common Voice 7.0 Hungarian
|
XLS-R-300M - Hungarian
|
31.099%
|
|||

|
Common Voice 8.0 Turkish
|
mpoyraz/wav2vec2-xls-r-300m-cv8-turkish
|
10.61%
|
|||

|
Common Voice 7.0 Armenian
|
XLS-R-300M - Armenian
|
101.627%
|
|||

|
Common Voice 7.0 Kyrgyz
|
XLS-R-300M - Kyrgyz
|
40.908%
|
|||

|
mozilla-foundation/common_voice_11_0 az
|
Whisper Large-V2 Azerbaijani - Drishti Sharma
|
|
|||

|
mozilla-foundation/common_voice_11_0 da
|
Whisper Medium Danish
|
|
|||

|
Common Voice 7.0 Bulgarian
|
XLS-R-300M - Bulgarian
|
46.68%
|
|||

|
Common Voice (Urdu)
|
wav2vec2-urdu
|
|
|||

|
Common Voice 7.0 Estonian
|
xls-r-et-cv_8_0
|
0.342%
|
|||

|
mozilla-foundation/common_voice_11_0 ro
|
Whisper Medium Romanian
|
|
|||

|
Common Voice 7.0 Hausa
|
XLS-R-300M - Hausa
|
100.0%
|
|||

|
Common Voice 7.0 French
|
XLS-R-300M - French
|
24.56%
|
|||

|
Common Voice 8.0 Uzbek
|
XLS-R-300M Uzbek CV8
|
|
|||

|
mozilla-foundation/common_voice_11_0 np-NP
|
Whisper Large Nepali - Drishti Sharma
|
|
|||

|
Common Voice 8.0 Greek
|
wav2vec2-large-xls-r-300m-el
|
|
|||

|
mozilla-foundation/common_voice_11_0 sw
|
Whisper Small Swahili
|
|
|||

|
mozilla-foundation/common_voice_16_0 yue
|
Whisper Small zh-HK - Alvin
|
|
|||

|
mozilla-foundation/common_voice_11_0 eu
|
openai/whisper-small
|
|
|||

|
mozilla-foundation/common_voice_10_0 uk
|
Whisper Small Ukranian
|
|
|||

|
Common Voice 7.0 Greek
|
XLS-R-300M - Greek
|
102.24%
|
|||

|
CommonVoice 6.1 (French)
|
asr-wav2vec2-commonvoice-fr
|
9.96%
|
|||

|
Common Voice 8.0 Chuvash
|
sammy786/wav2vec2-xlsr-chuvash
|
27.81%
|
|||

|
Common Voice 8.0 Kabyle
|
Akashpb13/Kabyle_xlsr
|
0.319%
|
|||

|
Common Voice 7.0 Georgian
|
XLS-R-300M - Georgian
|
42.09%
|
|||

|
Common Voice Catalan
|
Catalan XLSR Wav2Vec Large 53
|
8.11%
|
|||

|
Common Voice
|
SimAdapter +
|
|
|||

|
Common Voice 8.0 Basque
|
xls-r-eus
|
0.179%
|
|||

|
Common Voice 8.0 Arabic
|
Sinai Voice Arabic Speech Recognition Model
|
0.181%
|
|||

|
Common Voice 7.0 Esperanto
|
wav2vec2-xls-r-300m-eo
|
34.72%
|
Papers
| Paper | Code | Results | Date | Stars |
|---|







