EVALution
Introduced by Santus et al. in EVALution 1.0: an Evolving Semantic Dataset for Training and Evaluation of Distributional Semantic Models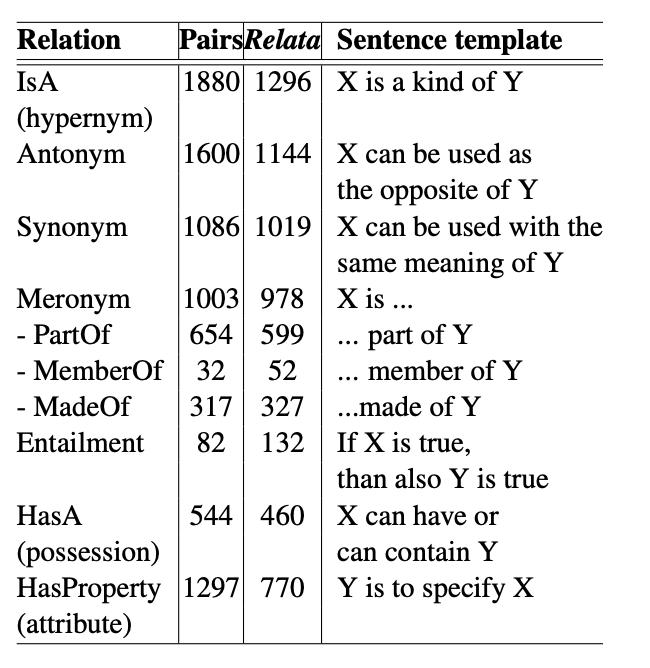
EVALution dataset is evenly distributed among the three classes (hypernyms, co-hyponyms and random) and involves three types of parts of speech (noun, verb, adjective). The full dataset contains a total of 4,263 distinct terms consisting of 2,380 nouns, 958 verbs and 972 adjectives.
Source: Network Features Based Co-hyponymy DetectionPapers
| Paper | Code | Results | Date | Stars |
|---|



