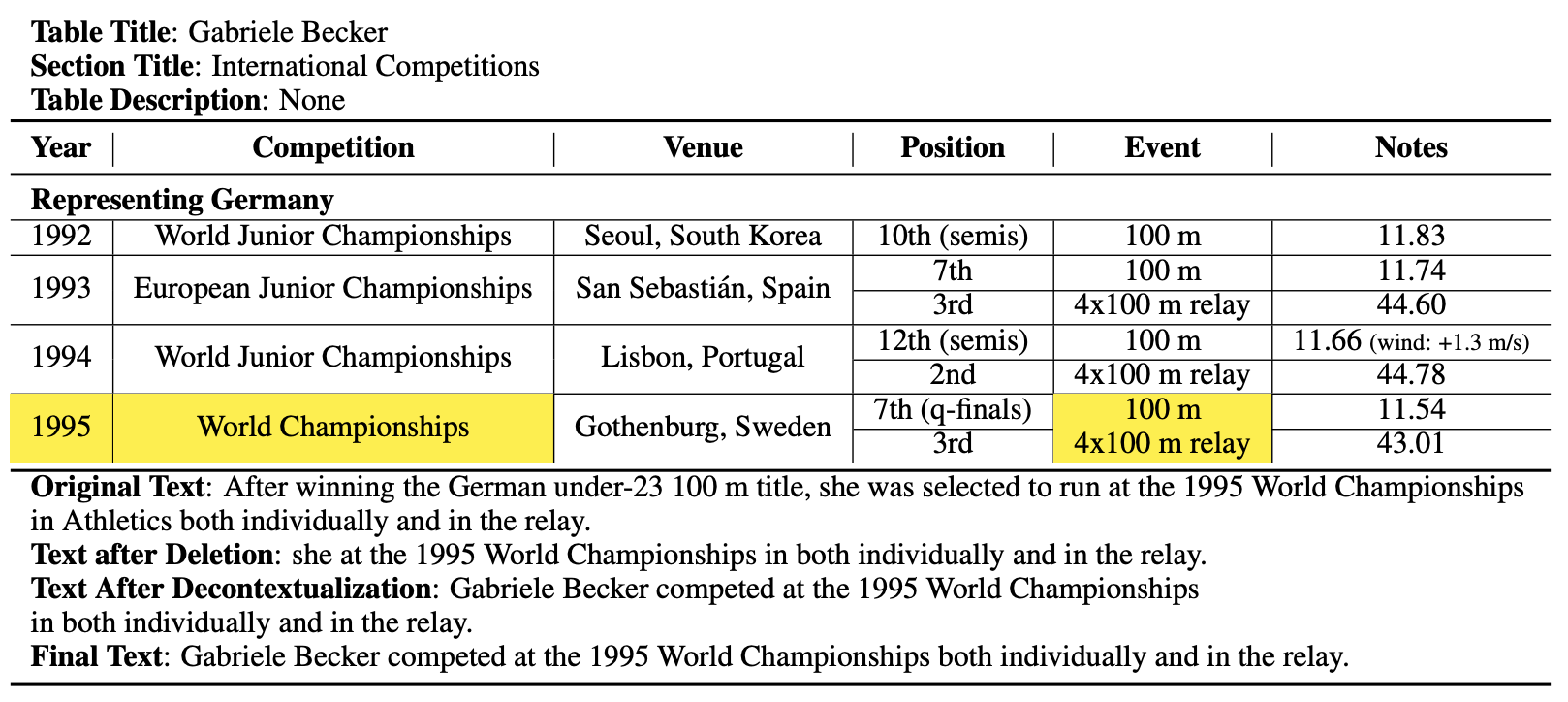
ToTTo is an open-domain English table-to-text dataset with over 120,000 training examples that proposes a controlled generation task: given a Wikipedia table and a set of highlighted table cells, produce a one-sentence description.
During the dataset creation process, tables from English Wikipedia are matched with (noisy) descriptions. Each table cell mentioned in the description is highlighted and the descriptions are iteratively cleaned and corrected to faithfully reflect the content of the highlighted cells.
Source: Google Research Datasets
Papers
| Paper | Code | Results | Date | Stars |
|---|





