TUT-SED Synthetic 2016
Introduced by Çakır et al. in Convolutional Recurrent Neural Networks for Polyphonic Sound Event Detection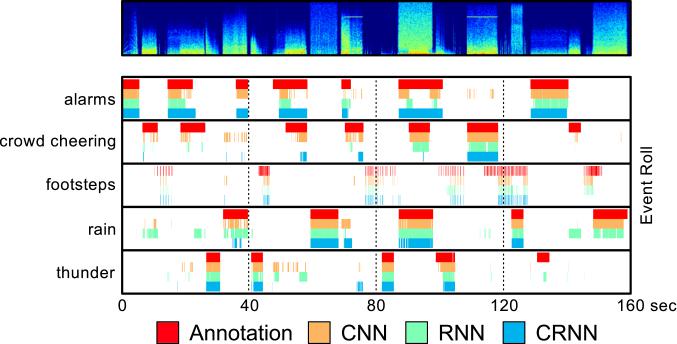
TUT-SED Synthetic 2016 contains of mixture signals artificially generated from isolated sound events samples. This approach is used to get more accurate onset and offset annotations than in dataset using recordings from real acoustic environments where the annotations are always subjective. Mixture signals in the dataset are created by randomly selecting and mixing isolated sound events from 16 sound event classes together. The resulting mixtures contains sound events with varying polyphony. All together 994 sound event samples were purchased from Sound Ideas. From the 100 mixtures created, 60% were assigned for training, 20% for testing and 20% for validation. The total amount of audio material in the dataset is 566 minutes. Different instances of the sound events are used to synthesize the training, validation and test partitions. Mixtures were created by randomly selecting event instance and from it, randomly, a segment of length 3-15 seconds. Between events, random length silent region was introduced. Such tracks were created for four to nine event classes, and were then mixed together to form the mixture signal. As sound events are not consistently active during the samples (e.g. footsteps), automatic signal energy based annotation was applied to obtain accurate event activity within the sample. Annotation of the mixture signal was created by pooling together event activity annotation of used samples.
Source: https://webpages.tuni.fi/arg/paper/taslp2017-crnn-sed/tut-sed-synthetic-2016Papers
| Paper | Code | Results | Date | Stars |
|---|


