UPFD (User Preference-aware Fake News Detection)
Introduced by Dou et al. in User Preference-aware Fake News Detection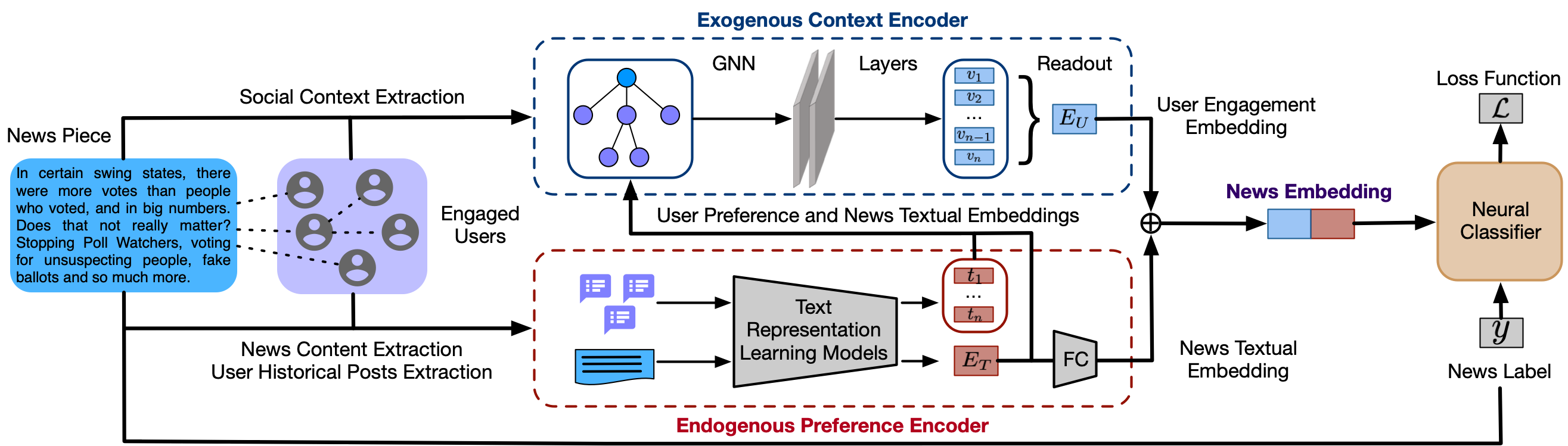
For benchmarking, please refer to its variant UPFD-POL and UPFD-GOS.
The dataset has been integrated with Pytorch Geometric (PyG) and Deep Graph Library (DGL). You can load the dataset after installing the latest versions of PyG or DGL.
The UPFD dataset includes two sets of tree-structured graphs curated for evaluating binary graph classification, graph anomaly detection, and fake/real news detection tasks. The dataset is dumped in the form of Pytorch-Geometric dataset object. You can easily load the data and run various GNN models using PyG.
The dataset includes fake&real news propagation (retweet) networks on Twitter built according to fact-check information from Politifact and Gossipcop. The news retweet graphs were originally extracted by FakeNewsNet. Each graph is a hierarchical tree-structured graph where the root node represents the news; the leaf nodes are Twitter users who retweeted the root news. A user node has an edge to the news node if he/she retweeted the news tweet. Two user nodes have an edge if one user retweeted the news tweet from the other user.
We crawled near 20 million historical tweets from users who participated in fake news propagation in FakeNewsNet to generate node features in the dataset.
We incorporate four node feature types in the dataset, the 768-dimensional bert and 300-dimensional spacy features
are encoded using pretrained BERT and spaCy word2vec, respectively.
The 10-dimensional profile feature is obtained from a Twitter account's profile.
You can refer to profile_feature.py for profile feature extraction.
The 310-dimensional content feature is composed of a 300-dimensional user comment word2vec (spaCy) embedding plus a 10-dimensional profile feature.
The dataset statistics is shown below:
| Data | #Graphs | #Fake News | #Total Nodes | #Total Edges | #Avg. Nodes per Graph |
|---|---|---|---|---|---|
| Politifact | 314 | 157 | 41,054 | 40,740 | 131 |
| Gossipcop | 5464 | 2732 | 314,262 | 308,798 | 58 |
Please refer to the paper for more details about the UPFD dataset.
Due to the Twitter policy, we could not release the crawled user's historical tweets publicly.
To get the corresponding Twitter user information, you can refer to the news lists under \data in our github repo
and map the news id to FakeNewsNet.
Then, you can crawl the user information by following the instruction on FakeNewsNet.
In the UPFD project, we use Tweepy and Twitter Developer API to get the user information.
Benchmarks
| Trend | Task | Dataset Variant | Best Model | Paper | Code |
|---|---|---|---|---|---|

|
UPFD-POL
|
HGFND
|
|||

|
UPFD-GOS
|
UPFD-SAGE
|
Papers
| Paper | Code | Results | Date | Stars |
|---|




