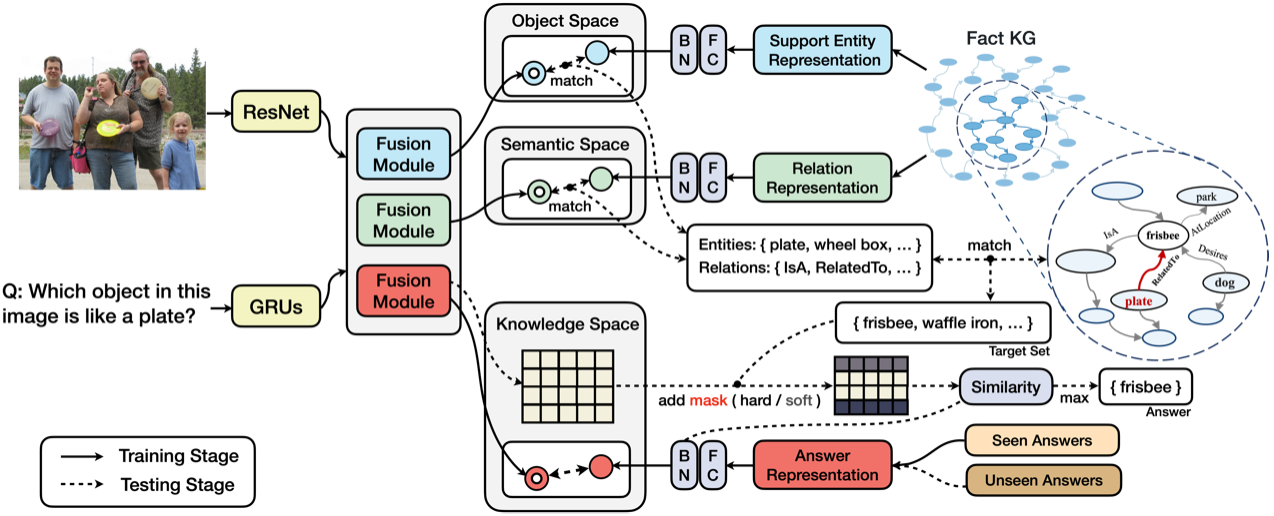
The ZS-F-VQA dataset is a new split of the F-VQA dataset for zero-shot problem. Firstly we obtain the original train/test split of F-VQA dataset and combine them together to filter out the triples whose answers appear in top-500 according to its occurrence frequency. Next, we randomly divide this set of answers into new training split (a.k.a. seen) $\mathcal{A}_s$ and testing split (a.k.a. unseen) $\mathcal{A}_u$ at the ratio of 1:1. With reference to F-VQA standard dataset, the division process is repeated 5 times. For each $(i,q,a)$ triplet in original F-VQA dataset, it is divided into training set if $a \in \mathcal{A}_s$. Else it is divided into testing set. The overlap of answer instance between training and testing set in F-VQA are $2565$ compared to $0$ in ZS-F-VQA.
Benchmarks
| Trend | Task | Dataset Variant | Best Model | Paper | Code |
|---|---|---|---|---|---|

|
ZS-F-VQA
|
SAN † - hard mask
|
Papers
| Paper | Code | Results | Date | Stars |
|---|


