 Self-Supervised Learning
Self-Supervised Learning
Barlow Twins
Introduced by Zbontar et al. in Barlow Twins: Self-Supervised Learning via Redundancy ReductionBarlow Twins is a self-supervised learning method that applies redundancy-reduction — a principle first proposed in neuroscience — to self supervised learning. The objective function measures the cross-correlation matrix between the embeddings of two identical networks fed with distorted versions of a batch of samples, and tries to make this matrix close to the identity. This causes the embedding vectors of distorted version of a sample to be similar, while minimizing the redundancy between the components of these vectors. Barlow Twins does not require large batches nor asymmetry between the network twins such as a predictor network, gradient stopping, or a moving average on the weight updates. Intriguingly it benefits from very high-dimensional output vectors.
Source: Barlow Twins: Self-Supervised Learning via Redundancy Reduction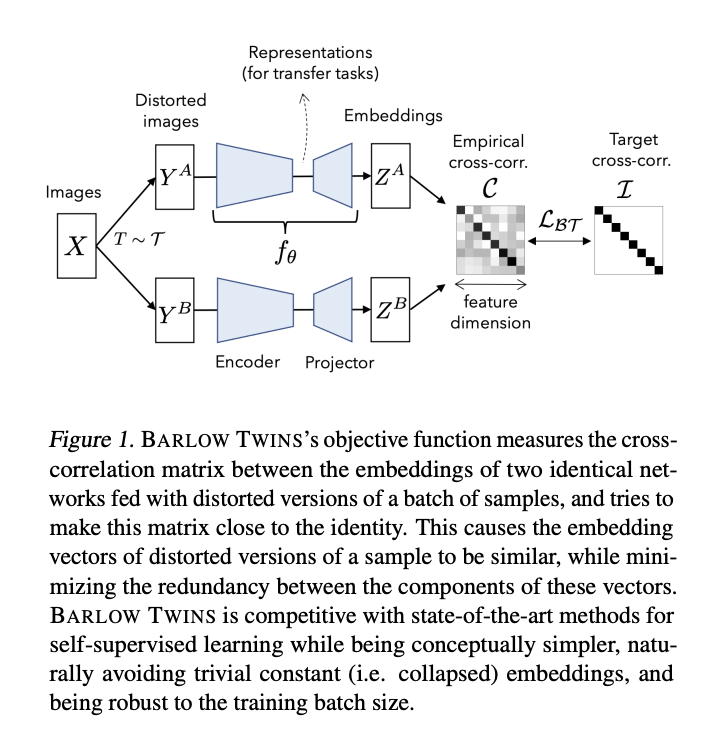
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Self-Supervised Learning | 41 | 35.65% |
| Image Classification | 5 | 4.35% |
| Semantic Segmentation | 4 | 3.48% |
| Language Modelling | 3 | 2.61% |
| Disentanglement | 3 | 2.61% |
| Domain Adaptation | 3 | 2.61% |
| Clustering | 2 | 1.74% |
| Image Segmentation | 2 | 1.74% |
| Federated Learning | 2 | 1.74% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
