 Self-Supervised Learning
Self-Supervised Learning
Bootstrap Your Own Latent
Introduced by Grill et al. in Bootstrap Your Own Latent - A New Approach to Self-Supervised LearningBYOL (Bootstrap Your Own Latent) is a new approach to self-supervised learning. BYOL’s goal is to learn a representation $y_θ$ which can then be used for downstream tasks. BYOL uses two neural networks to learn: the online and target networks. The online network is defined by a set of weights $θ$ and is comprised of three stages: an encoder $f_θ$, a projector $g_θ$ and a predictor $q_θ$. The target network has the same architecture as the online network, but uses a different set of weights $ξ$. The target network provides the regression targets to train the online network, and its parameters $ξ$ are an exponential moving average of the online parameters $θ$.
Given the architecture diagram on the right, BYOL minimizes a similarity loss between $q_θ(z_θ)$ and $sg(z'{_ξ})$, where $θ$ are the trained weights, $ξ$ are an exponential moving average of $θ$ and $sg$ means stop-gradient. At the end of training, everything but $f_θ$ is discarded, and $y_θ$ is used as the image representation.
Source: Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning
Image credit: Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning
Source: Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning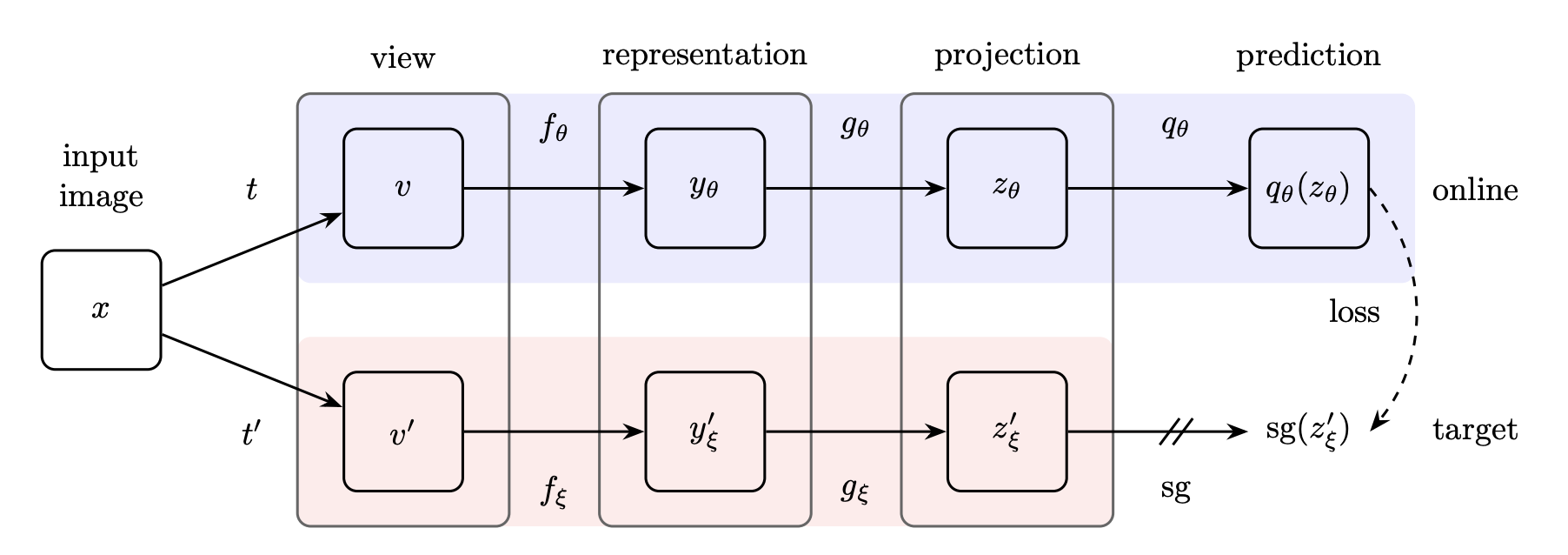
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Self-Supervised Learning | 72 | 38.71% |
| Image Classification | 10 | 5.38% |
| Semantic Segmentation | 7 | 3.76% |
| Object Detection | 6 | 3.23% |
| Time Series Analysis | 4 | 2.15% |
| Disentanglement | 3 | 1.61% |
| Pseudo Label | 3 | 1.61% |
| Depth Estimation | 3 | 1.61% |
| Few-Shot Learning | 3 | 1.61% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
