 Text-to-Speech Models
Text-to-Speech Models
ClariNet
Introduced by Ping et al. in ClariNet: Parallel Wave Generation in End-to-End Text-to-SpeechClariNet is an end-to-end text-to-speech architecture. Unlike previous TTS systems which use text-to-spectogram models with a separate waveform synthesizer (vocoder), ClariNet is a text-to-wave architecture that is fully convolutional and can be trained from scratch. In ClariNet, the WaveNet module is conditioned on the hidden states instead of the mel-spectogram. The architecture is otherwise based on Deep Voice 3.
Source: ClariNet: Parallel Wave Generation in End-to-End Text-to-Speech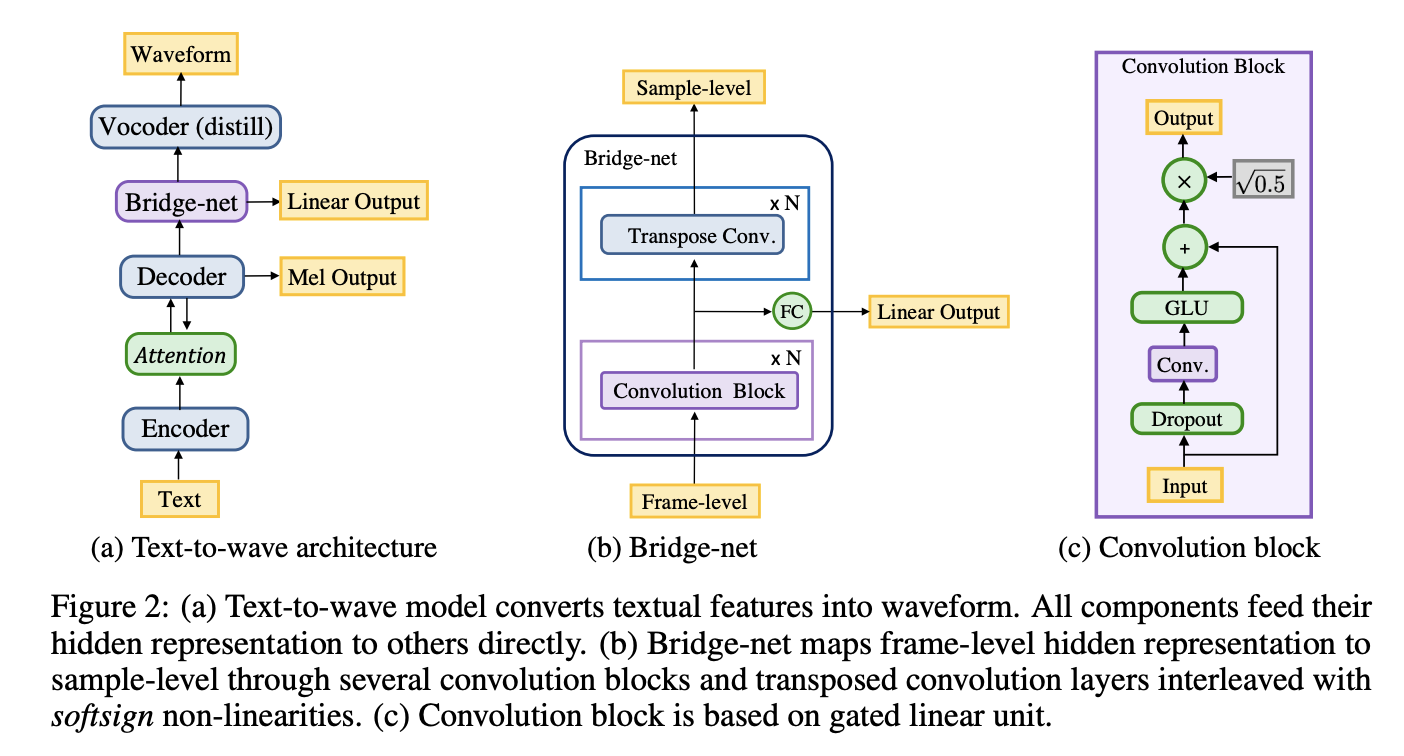
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Speech Synthesis | 3 | 30.00% |
| Domain Adaptation | 2 | 20.00% |
| Unsupervised Domain Adaptation | 2 | 20.00% |
| Melody Extraction | 1 | 10.00% |
| Retrieval | 1 | 10.00% |
| Text-To-Speech Synthesis | 1 | 10.00% |
 Bridge-net
Bridge-net
 Dense Connections
Dense Connections
 DV3 Attention Block
DV3 Attention Block
 DV3 Convolution Block
DV3 Convolution Block
 L1 Regularization
L1 Regularization
 Leaky ReLU
Leaky ReLU
 Normalizing Flows
Normalizing Flows
 ReLU
ReLU
 Softsign Activation
Softsign Activation
 WaveNet
WaveNet
 Weight Normalization
Weight Normalization
