 Semantic Segmentation Models
Semantic Segmentation Models
DeepLabv3
Introduced by Chen et al. in Rethinking Atrous Convolution for Semantic Image SegmentationDeepLabv3 is a semantic segmentation architecture that improves upon DeepLabv2 with several modifications. To handle the problem of segmenting objects at multiple scales, modules are designed which employ atrous convolution in cascade or in parallel to capture multi-scale context by adopting multiple atrous rates. Furthermore, the Atrous Spatial Pyramid Pooling module from DeepLabv2 augmented with image-level features encoding global context and further boost performance.
The changes to the ASSP module are that the authors apply global average pooling on the last feature map of the model, feed the resulting image-level features to a 1 × 1 convolution with 256 filters (and batch normalization), and then bilinearly upsample the feature to the desired spatial dimension. In the end, the improved ASPP consists of (a) one 1×1 convolution and three 3 × 3 convolutions with rates = (6, 12, 18) when output stride = 16 (all with 256 filters and batch normalization), and (b) the image-level features.
Another interesting difference is that DenseCRF post-processing from DeepLabv2 is no longer needed.
Source: Rethinking Atrous Convolution for Semantic Image Segmentation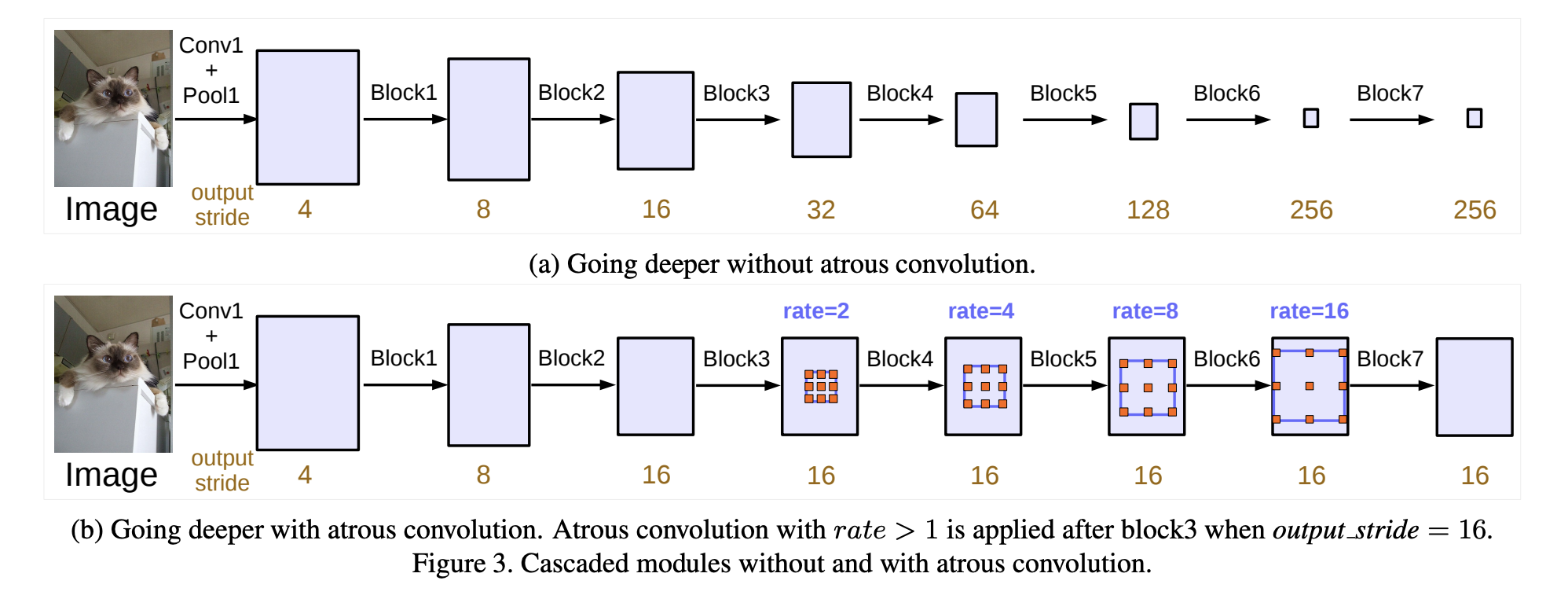
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Semantic Segmentation | 32 | 25.81% |
| Image Segmentation | 9 | 7.26% |
| Object Detection | 8 | 6.45% |
| Instance Segmentation | 7 | 5.65% |
| Image Classification | 6 | 4.84% |
| Classification | 3 | 2.42% |
| Image Augmentation | 2 | 1.61% |
| Thermal Image Segmentation | 2 | 1.61% |
| Medical Image Segmentation | 2 | 1.61% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
 1x1 Convolution
1x1 Convolution
|
Convolutions | |
 ASPP
ASPP
|
Semantic Segmentation Modules | |
 Batch Normalization
Batch Normalization
|
Normalization | |
 Dilated Convolution
Dilated Convolution
|
Convolutions |
