 Image Models
Image Models
Data-efficient Image Transformer
Introduced by Touvron et al. in Training data-efficient image transformers & distillation through attentionA Data-Efficient Image Transformer is a type of Vision Transformer for image classification tasks. The model is trained using a teacher-student strategy specific to transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention.
Source: Training data-efficient image transformers & distillation through attention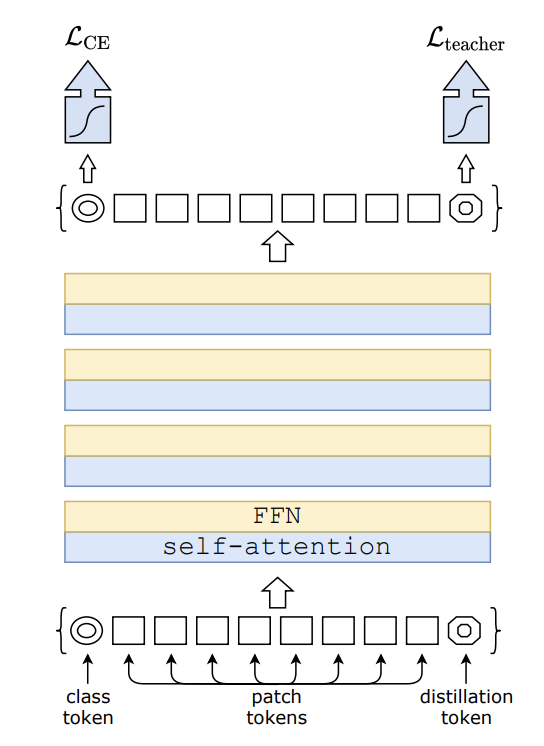
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Image Classification | 22 | 20.37% |
| Object Detection | 10 | 9.26% |
| Semantic Segmentation | 8 | 7.41% |
| Quantization | 7 | 6.48% |
| Self-Supervised Learning | 5 | 4.63% |
| Efficient ViTs | 4 | 3.70% |
| Fine-Grained Image Classification | 4 | 3.70% |
| Document Image Classification | 3 | 2.78% |
| Document Layout Analysis | 3 | 2.78% |
 Attention Dropout
Attention Dropout
 Dropout
Dropout
 Feedforward Network
Feedforward Network
 Multi-Head Attention
Multi-Head Attention
 Scaled Dot-Product Attention
Scaled Dot-Product Attention

