 Q-Learning Networks
Q-Learning Networks
Deep Q-Network
Introduced by Mnih et al. in Playing Atari with Deep Reinforcement LearningA DQN, or Deep Q-Network, approximates a state-value function in a Q-Learning framework with a neural network. In the Atari Games case, they take in several frames of the game as an input and output state values for each action as an output.
It is usually used in conjunction with Experience Replay, for storing the episode steps in memory for off-policy learning, where samples are drawn from the replay memory at random. Additionally, the Q-Network is usually optimized towards a frozen target network that is periodically updated with the latest weights every $k$ steps (where $k$ is a hyperparameter). The latter makes training more stable by preventing short-term oscillations from a moving target. The former tackles autocorrelation that would occur from on-line learning, and having a replay memory makes the problem more like a supervised learning problem.
Image Source: here
Source: Playing Atari with Deep Reinforcement Learning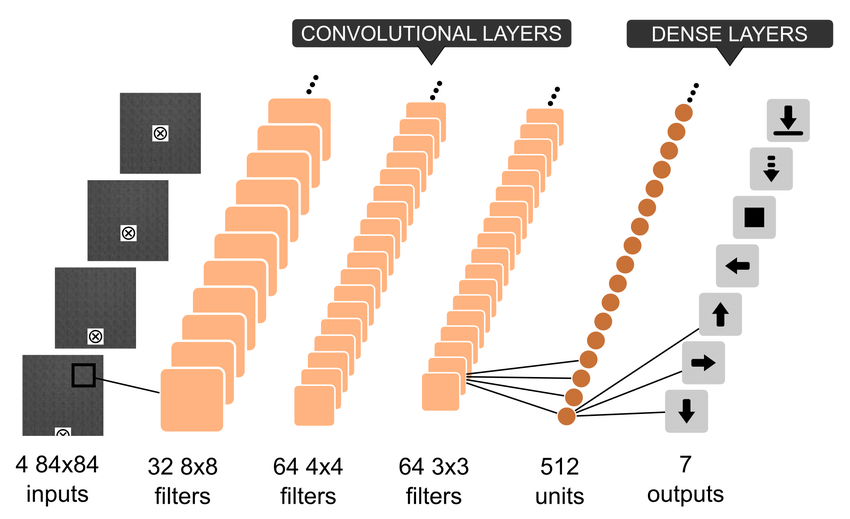
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Reinforcement Learning (RL) | 277 | 39.01% |
| Atari Games | 65 | 9.15% |
| Decision Making | 34 | 4.79% |
| Management | 18 | 2.54% |
| Multi-agent Reinforcement Learning | 14 | 1.97% |
| Efficient Exploration | 14 | 1.97% |
| OpenAI Gym | 12 | 1.69% |
| Autonomous Driving | 11 | 1.55% |
| Continuous Control | 9 | 1.27% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
 Convolution
Convolution
|
Convolutions | |
 Dense Connections
Dense Connections
|
Feedforward Networks | |
 Q-Learning
Q-Learning
|
Off-Policy TD Control |
