 Generative Models
Generative Models
DVD-GAN
Introduced by Clark et al. in Adversarial Video Generation on Complex DatasetsDVD-GAN is a generative adversarial network for video generation built upon the BigGAN architecture.
DVD-GAN uses two discriminators: a Spatial Discriminator $\mathcal{D}_{S}$ and a Temporal Discriminator $\mathcal{D}_{T}$. $\mathcal{D}_{S}$ critiques single frame content and structure by randomly sampling $k$ full-resolution frames and judging them individually. The temporal discriminator $\mathcal{D}_{T}$ must provide $G$ with the learning signal to generate movement (not evaluated by $\mathcal{D}_{S}$).
The input to $G$ consists of a Gaussian latent noise $z \sim N\left(0, I\right)$ and a learned linear embedding $e\left(y\right)$ of the desired class $y$. Both inputs are 120-dimensional vectors. $G$ starts by computing an affine transformation of $\left[z; e\left(y\right)\right]$ to a $\left[4, 4, ch_{0}\right]$-shaped tensor. $\left[z; e\left(y\right)\right]$ is used as the input to all class-conditional Batch Normalization layers throughout $G$. This is then treated as the input (at each frame we would like to generate) to a Convolutional GRU.
This RNN is unrolled once per frame. The output of this RNN is processed by two residual blocks. The time dimension is combined with the batch dimension here, so each frame proceeds through the blocks independently. The output of these blocks has width and height dimensions which are doubled (we skip upsampling in the first block). This is repeated a number of times, with the output of one RNN + residual group fed as the input to the next group, until the output tensors have the desired spatial dimensions.
The spatial discriminator $\mathcal{D}_{S}$ functions almost identically to BigGAN’s discriminator. A score is calculated for each of the uniformly sampled $k$ frames (default $k = 8$) and the $\mathcal{D}_{S}$ output is the sum over per-frame scores. The temporal discriminator $\mathcal{D}_{T}$ has a similar architecture, but pre-processes the real or generated video with a $2 \times 2$ average-pooling downsampling function $\phi$. Furthermore, the first two residual blocks of $\mathcal{D}_{T}$ are 3-D, where every convolution is replaced with a 3-D convolution with a kernel size of $3 \times 3 \times 3$. The rest of the architecture follows BigGAN.
Source: Adversarial Video Generation on Complex Datasets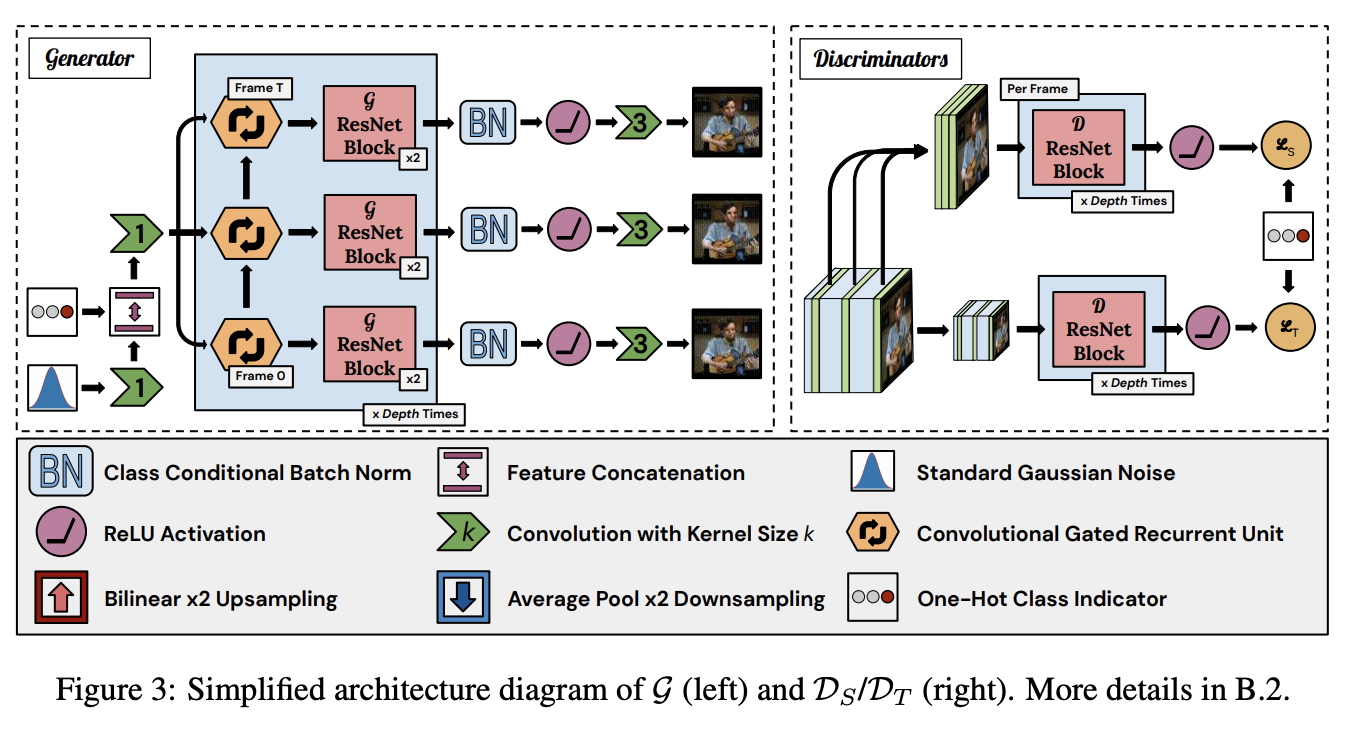
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| 3D Character Animation From A Single Photo | 1 | 33.33% |
| Video Generation | 1 | 33.33% |
| Video Prediction | 1 | 33.33% |
 1x1 Convolution
1x1 Convolution
 CGRU
CGRU
 Conditional Batch Normalization
Conditional Batch Normalization
 DVD-GAN DBlock
DVD-GAN DBlock
 DVD-GAN GBlock
DVD-GAN GBlock
 Early Stopping
Early Stopping
 GAN Hinge Loss
GAN Hinge Loss
 Leaky ReLU
Leaky ReLU
 Orthogonal Regularization
Orthogonal Regularization
 Projection Discriminator
Projection Discriminator
 ReLU
ReLU
 Spectral Normalization
Spectral Normalization
 TTUR
TTUR


