 Attention Patterns
Attention Patterns
Global and Sliding Window Attention
Introduced by Beltagy et al. in Longformer: The Long-Document TransformerGlobal and Sliding Window Attention is an attention pattern for attention-based models. It is motivated by the fact that non-sparse attention in the original Transformer formulation has a self-attention component with $O\left(n^{2}\right)$ time and memory complexity where $n$ is the input sequence length and thus, is not efficient to scale to long inputs.
Since windowed and dilated attention patterns are not flexible enough to learn task-specific representations, the authors of the Longformer add “global attention” on few pre-selected input locations. This attention is operation symmetric: that is, a token with a global attention attends to all tokens across the sequence, and all tokens in the sequence attend to it. The Figure to the right shows an example of a sliding window attention with global attention at a few tokens at custom locations. For the example of classification, global attention is used for the [CLS] token, while in the example of Question Answering, global attention is provided on all question tokens.
Source: Longformer: The Long-Document Transformer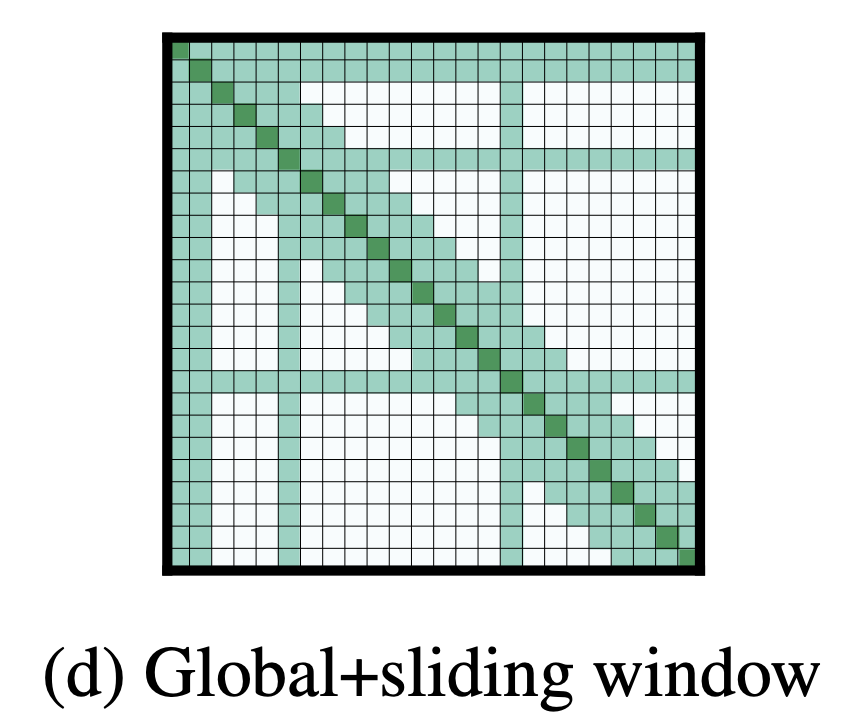
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Language Modelling | 14 | 10.07% |
| Sentence | 10 | 7.19% |
| Document Classification | 10 | 7.19% |
| Question Answering | 9 | 6.47% |
| Classification | 6 | 4.32% |
| Text Classification | 5 | 3.60% |
| Natural Language Inference | 5 | 3.60% |
| Abstractive Text Summarization | 5 | 3.60% |
| Text Summarization | 4 | 2.88% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
