 Image Data Augmentation
Image Data Augmentation
Greedy Policy Search
Introduced by Molchanov et al. in Greedy Policy Search: A Simple Baseline for Learnable Test-Time AugmentationGreedy Policy Search (GPS) is a simple algorithm that learns a policy for test-time data augmentation based on the predictive performance on a validation set. GPS starts with an empty policy and builds it in an iterative fashion. Each step selects a sub-policy that provides the largest improvement in calibrated log-likelihood of ensemble predictions and adds it to the current policy.
Source: Greedy Policy Search: A Simple Baseline for Learnable Test-Time Augmentation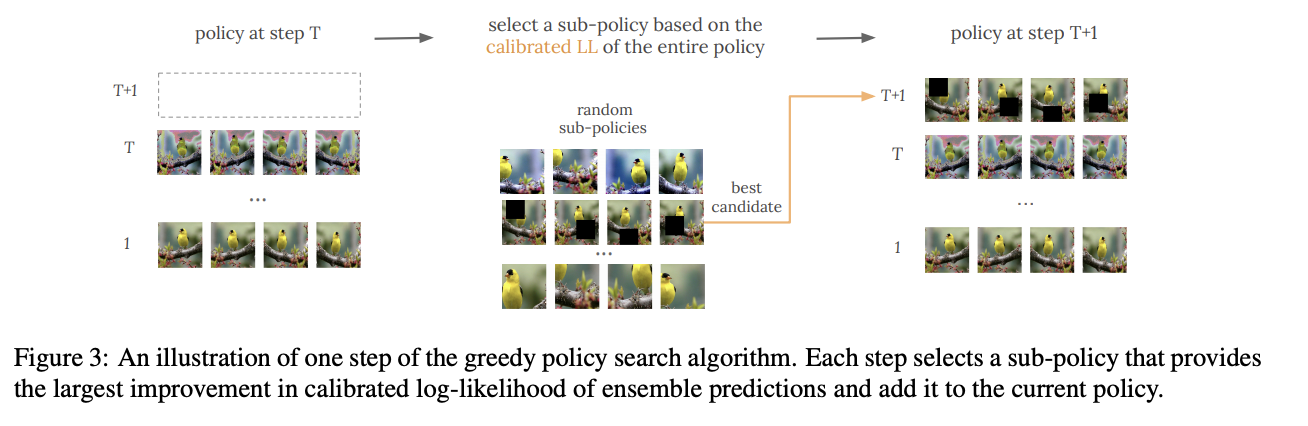
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Autonomous Driving | 21 | 4.17% |
| Management | 17 | 3.37% |
| Object Detection | 16 | 3.17% |
| Bayesian Optimization | 15 | 2.98% |
| Uncertainty Quantification | 15 | 2.98% |
| Time Series Analysis | 15 | 2.98% |
| Autonomous Vehicles | 12 | 2.38% |
| Semantic Segmentation | 12 | 2.38% |
| Decision Making | 11 | 2.18% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
