 Image Generation Models
Image Generation Models
Group Decreasing Network
Introduced by Zhu et al. in Semantically Multi-modal Image SynthesisGroup Decreasing Network, or GroupDNet, is a type of convolutional neural network for multi-modal image synthesis. GroupDNet contains one encoder and one decoder. Inspired by the idea of VAE and SPADE, the encoder $E$ produces a latent code $Z$ that is supposed to follow a Gaussian distribution $\mathcal{N}(0,1)$ during training. While testing, the encoder $E$ is discarded. A randomly sampled code from the Gaussian distribution substitutes for $Z$. To fulfill this, the re-parameterization trick is used to enable a differentiable loss function during training. Specifically, the encoder predicts a mean vector and a variance vector through two fully connected layers to represent the encoded distribution. The gap between the encoded distribution and Gaussian distribution can be minimized by imposing a KL-divergence loss.
Source: Semantically Multi-modal Image Synthesis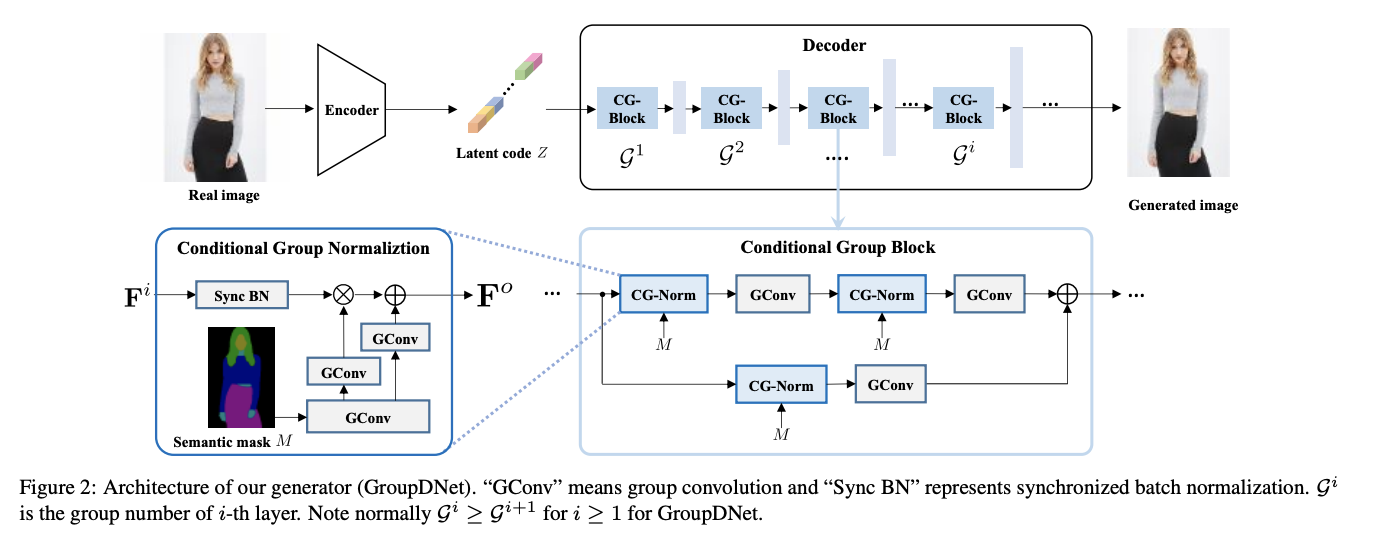
Papers
| Paper | Code | Results | Date | Stars |
|---|
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
