 Clustering
Clustering
k-Means Clustering
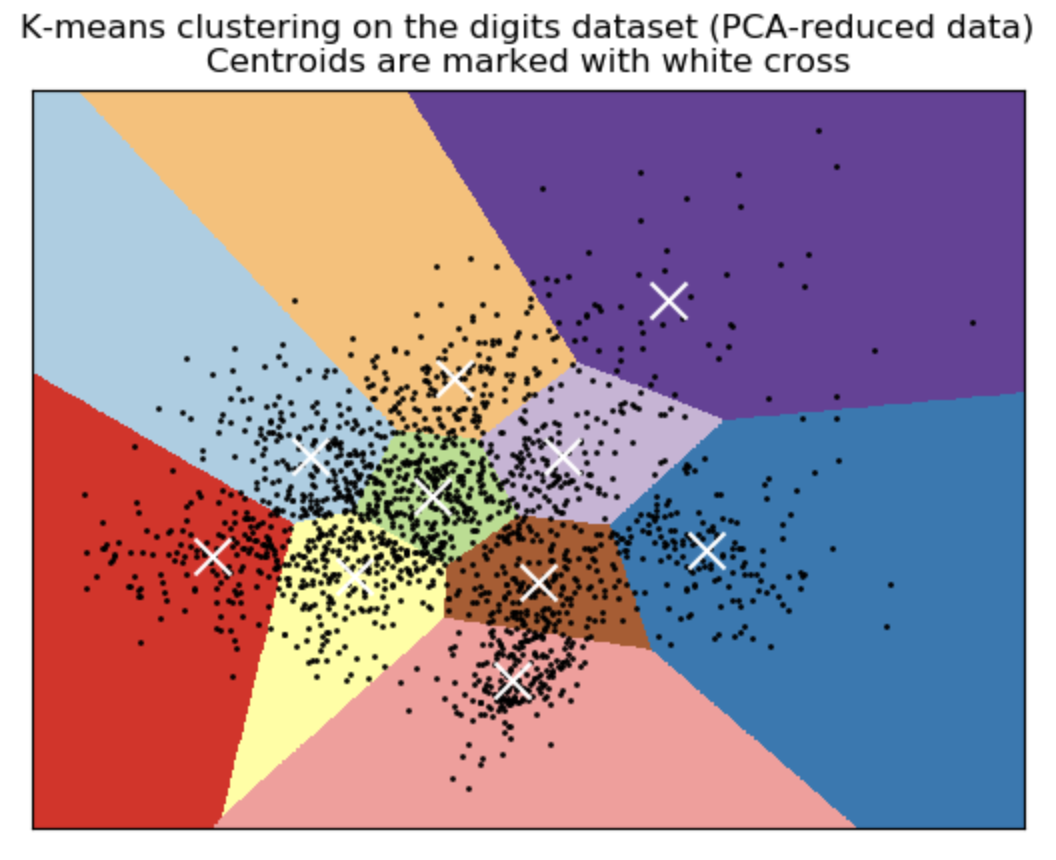
k-Means Clustering is a clustering algorithm that divides a training set into $k$ different clusters of examples that are near each other. It works by initializing $k$ different centroids {$\mu\left(1\right),\ldots,\mu\left(k\right)$} to different values, then alternating between two steps until convergence:
(i) each training example is assigned to cluster $i$ where $i$ is the index of the nearest centroid $\mu^{(i)}$
(ii) each centroid $\mu^{(i)}$ is updated to the mean of all training examples $x^{(j)}$ assigned to cluster $i$.
Text Source: Deep Learning, Goodfellow et al
Image Source: scikit-learn
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Clustering | 187 | 19.64% |
| Object Detection | 129 | 13.55% |
| Semantic Segmentation | 27 | 2.84% |
| Autonomous Driving | 21 | 2.21% |
| Classification | 17 | 1.79% |
| Image Classification | 14 | 1.47% |
| Real-Time Object Detection | 13 | 1.37% |
| Quantization | 12 | 1.26% |
| Self-Supervised Learning | 12 | 1.26% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
