 Generalized Additive Models
Generalized Additive Models
Neural Additive Model
Introduced by Agarwal et al. in Neural Additive Models: Interpretable Machine Learning with Neural NetsNeural Additive Models (NAMs) make restrictions on the structure of neural networks, which yields a family of models that are inherently interpretable while suffering little loss in prediction accuracy when applied to tabular data. Methodologically, NAMs belong to a larger model family called Generalized Additive Models (GAMs).
NAMs learn a linear combination of networks that each attend to a single input feature: each $f_{i}$ in the traditional GAM formulationis parametrized by a neural network. These networks are trained jointly using backpropagation and can learn arbitrarily complex shape functions. Interpreting NAMs is easy as the impact of a feature on the prediction does not rely on the other features and can be understood by visualizing its corresponding shape function (e.g., plotting $f_{i}\left(x_{i}\right)$ vs. $x_{i}$).
Source: Neural Additive Models: Interpretable Machine Learning with Neural Nets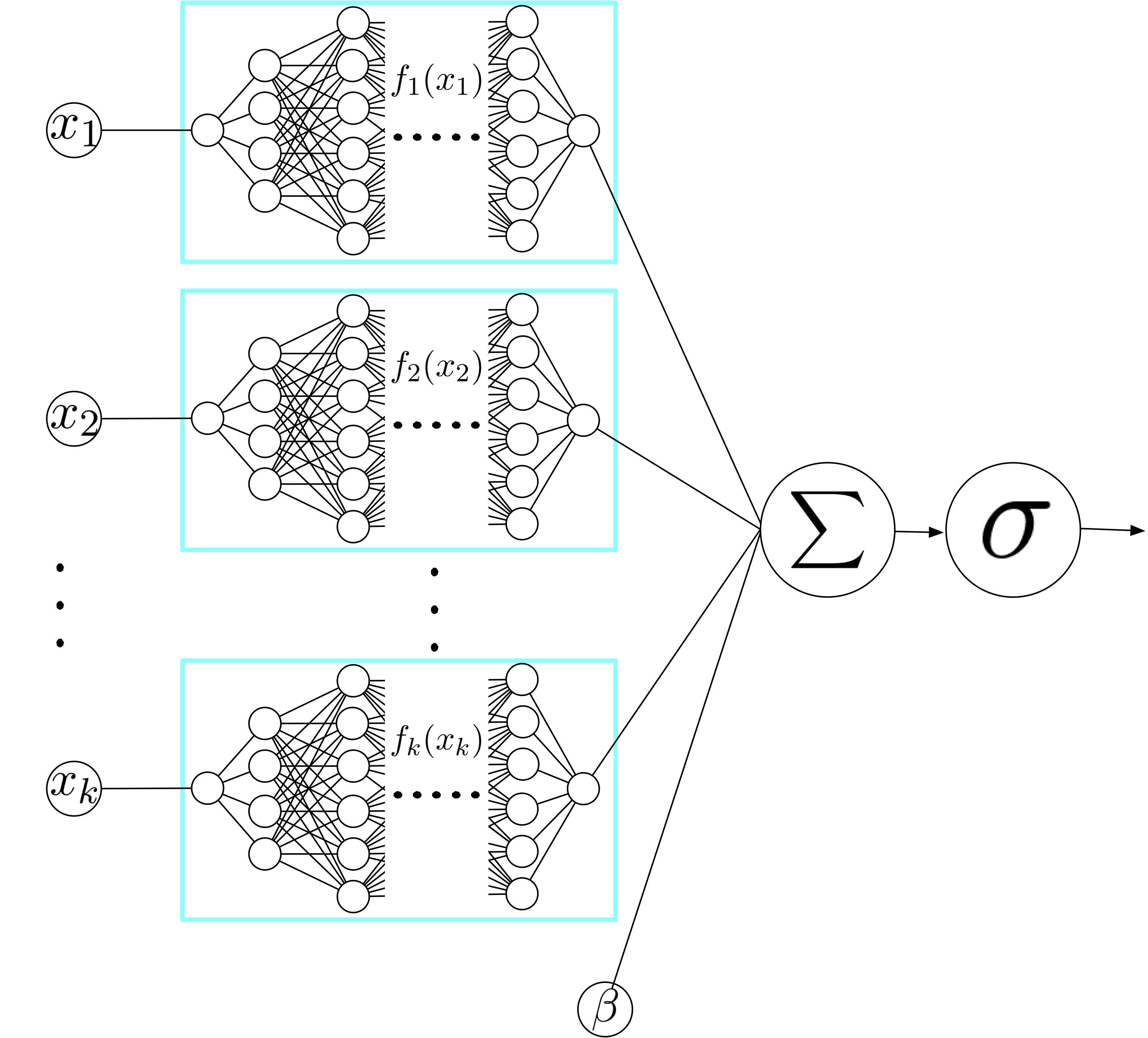
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Additive models | 6 | 24.00% |
| Interpretable Machine Learning | 3 | 12.00% |
| BIG-bench Machine Learning | 3 | 12.00% |
| Survival Analysis | 2 | 8.00% |
| Decision Making | 2 | 8.00% |
| Explainable Models | 1 | 4.00% |
| Image Segmentation | 1 | 4.00% |
| Semantic Segmentation | 1 | 4.00% |
| Classification | 1 | 4.00% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |

