 Semantic Segmentation Models
Semantic Segmentation Models
nnFormer
Introduced by Zhou et al. in nnFormer: Interleaved Transformer for Volumetric SegmentationnnFormer, or not-another transFormer, is a semantic segmentation model with an interleaved architecture based on empirical combination of self-attention and convolution. Firstly, a light-weight convolutional embedding layer ahead is used ahead of transformer blocks. In comparison to directly flattening raw pixels and applying 1D pre-processing, the convolutional embedding layer encodes precise (i.e., pixel-level) spatial information and provide low-level yet high-resolution 3D features. After the embedding block, transformer and convolutional down-sampling blocks are interleaved to fully entangle long-term dependencies with high-level and hierarchical object concepts at various scales, which helps improve the generalization ability and robustness of learned representations.
Source: nnFormer: Interleaved Transformer for Volumetric Segmentation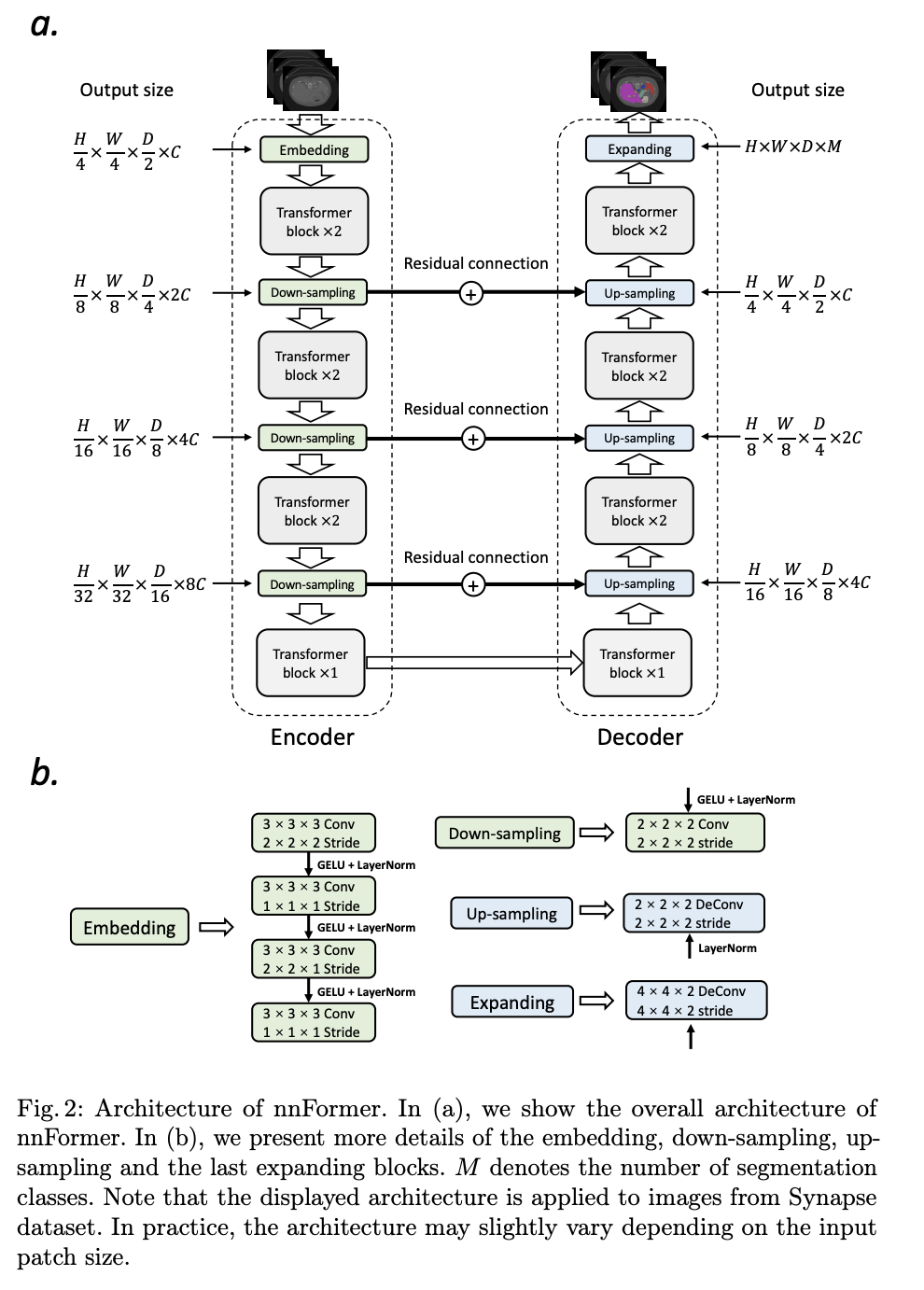
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Image Segmentation | 2 | 33.33% |
| Semantic Segmentation | 2 | 33.33% |
| Medical Image Segmentation | 1 | 16.67% |
| Volumetric Medical Image Segmentation | 1 | 16.67% |
 Convolution
Convolution
 GELU
GELU
 Layer Normalization
Layer Normalization
 Multi-Head Attention
Multi-Head Attention
 Residual Connection
Residual Connection
 Scaled Dot-Product Attention
Scaled Dot-Product Attention

