 Semi-Supervised Learning Methods
Semi-Supervised Learning Methods
Noisy Student
Introduced by Xie et al. in Self-training with Noisy Student improves ImageNet classificationNoisy Student Training is a semi-supervised learning approach. It extends the idea of self-training and distillation with the use of equal-or-larger student models and noise added to the student during learning. It has three main steps:
- train a teacher model on labeled images
- use the teacher to generate pseudo labels on unlabeled images
- train a student model on the combination of labeled images and pseudo labeled images.
The algorithm is iterated a few times by treating the student as a teacher to relabel the unlabeled data and training a new student.
Noisy Student Training seeks to improve on self-training and distillation in two ways. First, it makes the student larger than, or at least equal to, the teacher so the student can better learn from a larger dataset. Second, it adds noise to the student so the noised student is forced to learn harder from the pseudo labels. To noise the student, it uses input noise such as RandAugment data augmentation, and model noise such as dropout and stochastic depth during training.
Source: Self-training with Noisy Student improves ImageNet classification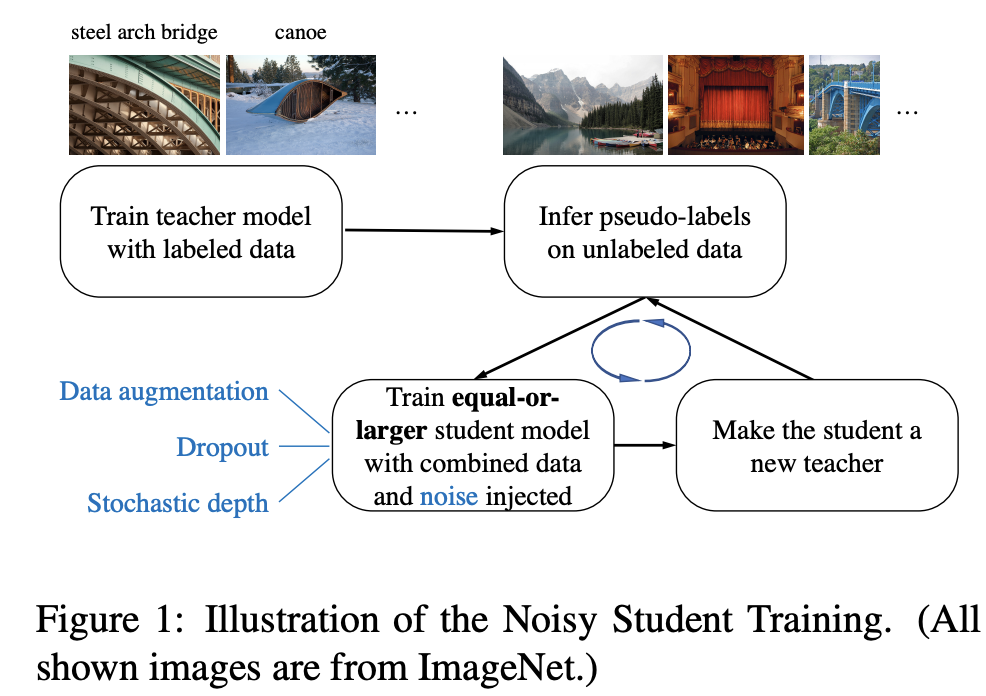
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Automatic Speech Recognition (ASR) | 6 | 9.68% |
| Speech Recognition | 6 | 9.68% |
| Image Classification | 6 | 9.68% |
| Pseudo Label | 4 | 6.45% |
| Self-Supervised Learning | 3 | 4.84% |
| Semantic Segmentation | 2 | 3.23% |
| Classification | 2 | 3.23% |
| Computed Tomography (CT) | 2 | 3.23% |
| General Classification | 2 | 3.23% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
 Dropout
Dropout
|
Regularization | |
 RandAugment
RandAugment
|
Image Data Augmentation | |
 Stochastic Depth
Stochastic Depth
|
Regularization |
