 Generative Models
Generative Models
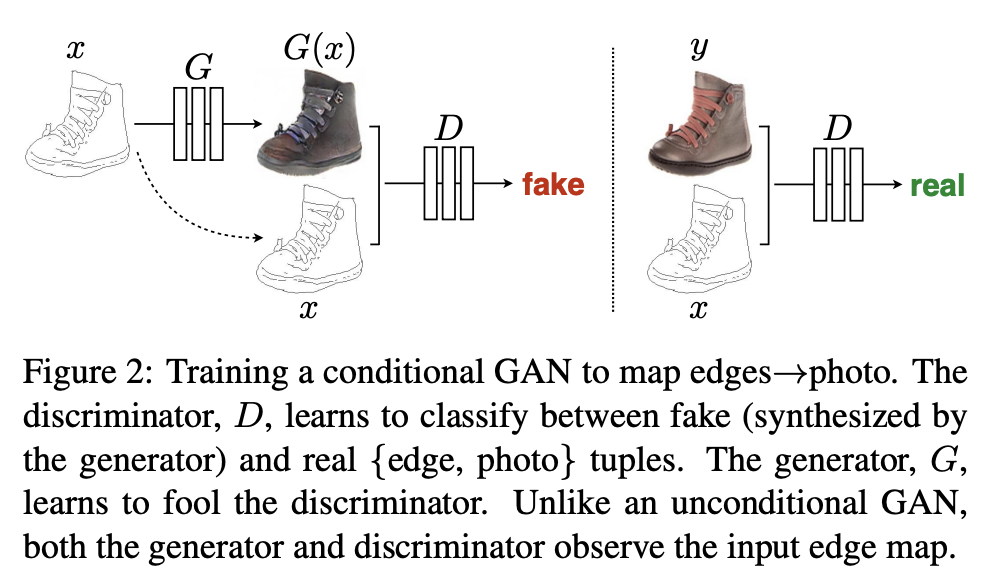
Pix2Pix
Introduced by Isola et al. in Image-to-Image Translation with Conditional Adversarial NetworksPix2Pix is a conditional image-to-image translation architecture that uses a conditional GAN objective combined with a reconstruction loss. The conditional GAN objective for observed images $x$, output images $y$ and the random noise vector $z$ is:
$$ \mathcal{L}_{cGAN}\left(G, D\right) =\mathbb{E}_{x,y}\left[\log D\left(x, y\right)\right]+ \mathbb{E}_{x,z}\left[log(1 − D\left(x, G\left(x, z\right)\right)\right] $$
We augment this with a reconstruction term:
$$ \mathcal{L}_{L1}\left(G\right) = \mathbb{E}_{x,y,z}\left[||y - G\left(x, z\right)||_{1}\right] $$
and we get the final objective as:
$$ G^{*} = \arg\min_{G}\max_{D}\mathcal{L}_{cGAN}\left(G, D\right) + \lambda\mathcal{L}_{L1}\left(G\right) $$
The architectures employed for the generator and discriminator closely follow DCGAN, with a few modifications:
- Concatenated skip connections are used to "shuttle" low-level information between the input and output, similar to a U-Net.
- The use of a PatchGAN discriminator that only penalizes structure at the scale of patches.
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Translation | 39 | 18.40% |
| Image-to-Image Translation | 33 | 15.57% |
| Image Generation | 16 | 7.55% |
| Semantic Segmentation | 8 | 3.77% |
| Style Transfer | 6 | 2.83% |
| Colorization | 6 | 2.83% |
| Anatomy | 4 | 1.89% |
| Conditional Image Generation | 3 | 1.42% |
| Image Classification | 3 | 1.42% |
 Batch Normalization
Batch Normalization
 Concatenated Skip Connection
Concatenated Skip Connection
 Convolution
Convolution
 Dropout
Dropout
 Leaky ReLU
Leaky ReLU
 PatchGAN
PatchGAN
 ReLU
ReLU
 Sigmoid Activation
Sigmoid Activation


