 Off-Policy TD Control
Off-Policy TD Control
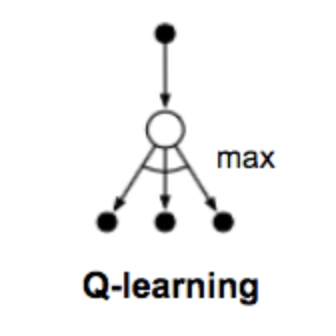
Q-Learning
Q-Learning is an off-policy temporal difference control algorithm:
$$Q\left(S_{t}, A_{t}\right) \leftarrow Q\left(S_{t}, A_{t}\right) + \alpha\left[R_{t+1} + \gamma\max_{a}Q\left(S_{t+1}, a\right) - Q\left(S_{t}, A_{t}\right)\right] $$
The learned action-value function $Q$ directly approximates $q_{*}$, the optimal action-value function, independent of the policy being followed.
Source: Sutton and Barto, Reinforcement Learning, 2nd Edition
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Reinforcement Learning (RL) | 206 | 34.28% |
| Decision Making | 48 | 7.99% |
| Multi-agent Reinforcement Learning | 27 | 4.49% |
| Offline RL | 26 | 4.33% |
| Management | 26 | 4.33% |
| Atari Games | 17 | 2.83% |
| OpenAI Gym | 13 | 2.16% |
| Continuous Control | 11 | 1.83% |
| Imitation Learning | 11 | 1.83% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
