 Value Function Estimation
Value Function Estimation
Retrace
Introduced by Munos et al. in Safe and Efficient Off-Policy Reinforcement LearningRetrace is an off-policy Q-value estimation algorithm which has guaranteed convergence for a target and behaviour policy $\left(\pi, \beta\right)$. With off-policy rollout for TD learning, we must use importance sampling for the update:
$$ \Delta{Q}^{\text{imp}}\left(S_{t}, A_{t}\right) = \gamma^{t}\prod_{1\leq{\tau}\leq{t}}\frac{\pi\left(A_{\tau}\mid{S_{\tau}}\right)}{\beta\left(A_{\tau}\mid{S_{\tau}}\right)}\delta_{t} $$
This product term can lead to high variance, so Retrace modifies $\Delta{Q}$ to have importance weights truncated by no more than a constant $c$:
$$ \Delta{Q}^{\text{imp}}\left(S_{t}, A_{t}\right) = \gamma^{t}\prod_{1\leq{\tau}\leq{t}}\min\left(c, \frac{\pi\left(A_{\tau}\mid{S_{\tau}}\right)}{\beta\left(A_{\tau}\mid{S_{\tau}}\right)}\right)\delta_{t} $$
Source: Safe and Efficient Off-Policy Reinforcement Learning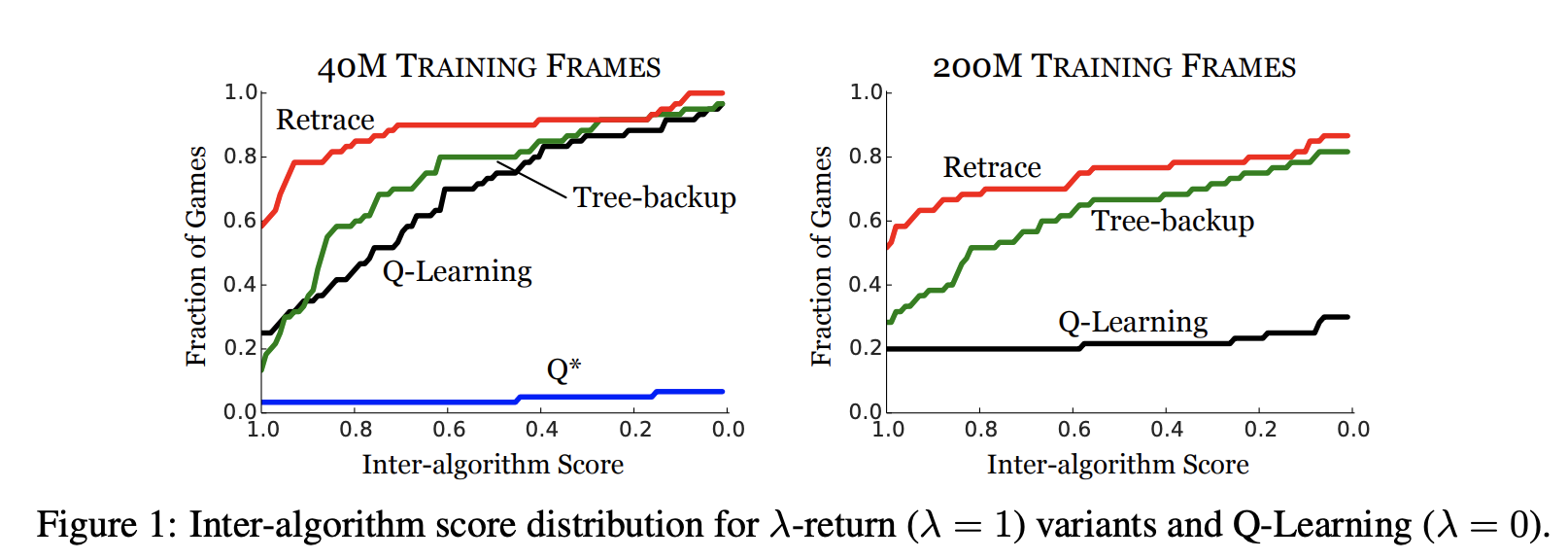
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Reinforcement Learning (RL) | 13 | 34.21% |
| Face Anti-Spoofing | 3 | 7.89% |
| Face Recognition | 3 | 7.89% |
| Time Series Analysis | 2 | 5.26% |
| Problem Decomposition | 2 | 5.26% |
| General Classification | 2 | 5.26% |
| Atari Games | 2 | 5.26% |
| Face Presentation Attack Detection | 1 | 2.63% |
| Decision Making | 1 | 2.63% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
