 Twin Networks
Twin Networks
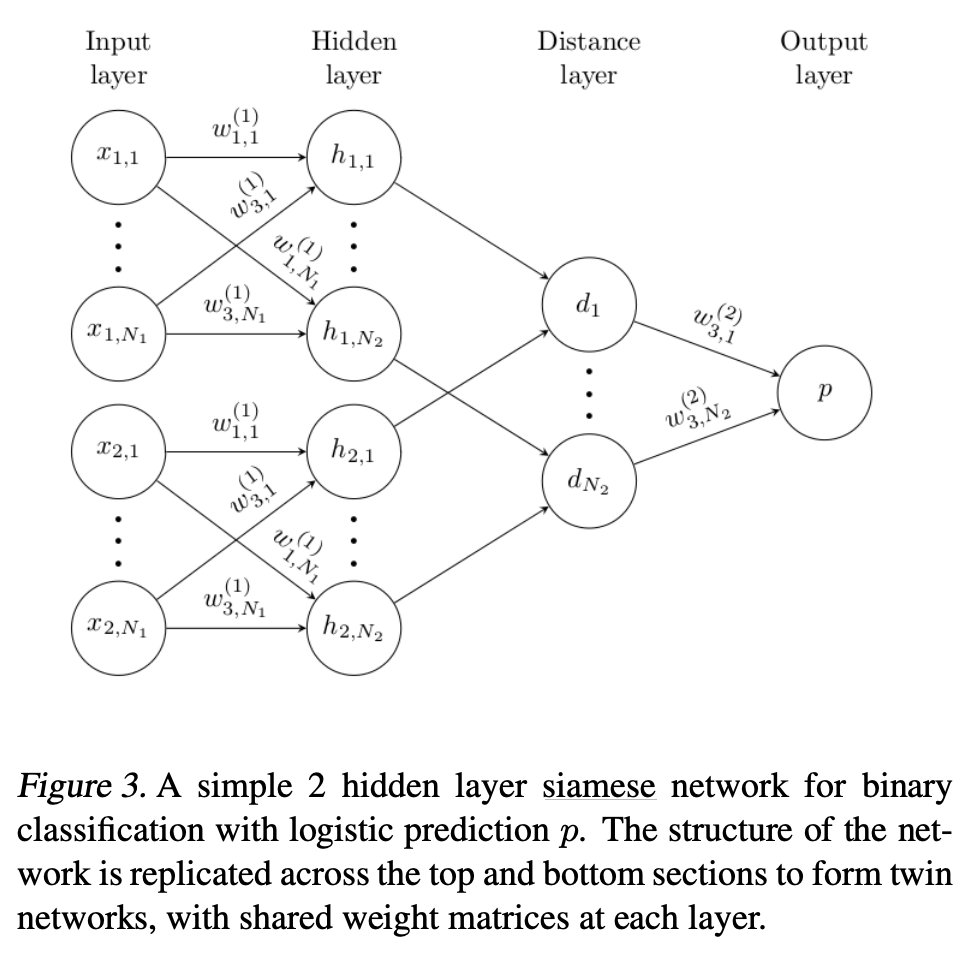
Siamese Network
A Siamese Network consists of twin networks which accept distinct inputs but are joined by an energy function at the top. This function computes a metric between the highest level feature representation on each side. The parameters between the twin networks are tied. Weight tying guarantees that two extremely similar images are not mapped by each network to very different locations in feature space because each network computes the same function. The network is symmetric, so that whenever we present two distinct images to the twin networks, the top conjoining layer will compute the same metric as if we were to we present the same two images but to the opposite twins.
Intuitively instead of trying to classify inputs, a siamese network learns to differentiate between inputs, learning their similarity. The loss function used is usually a form of contrastive loss.
Source: Koch et al
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Object Tracking | 32 | 5.21% |
| Retrieval | 22 | 3.58% |
| Self-Supervised Learning | 18 | 2.93% |
| Visual Tracking | 17 | 2.77% |
| Visual Object Tracking | 16 | 2.61% |
| Change Detection | 16 | 2.61% |
| Object Detection | 15 | 2.44% |
| Classification | 14 | 2.28% |
| Semantic Segmentation | 13 | 2.12% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
