 Transformers
Transformers
Sparse Transformer
Introduced by Child et al. in Generating Long Sequences with Sparse TransformersA Sparse Transformer is a Transformer based architecture which utilises sparse factorizations of the attention matrix to reduce time/memory to $O(n \sqrt{n})$. Other changes to the Transformer architecture include: (a) a restructured residual block and weight initialization, (b) A set of sparse attention kernels which efficiently compute subsets of the attention matrix, (c) recomputation of attention weights during the backwards pass to reduce memory usage
Source: Generating Long Sequences with Sparse Transformers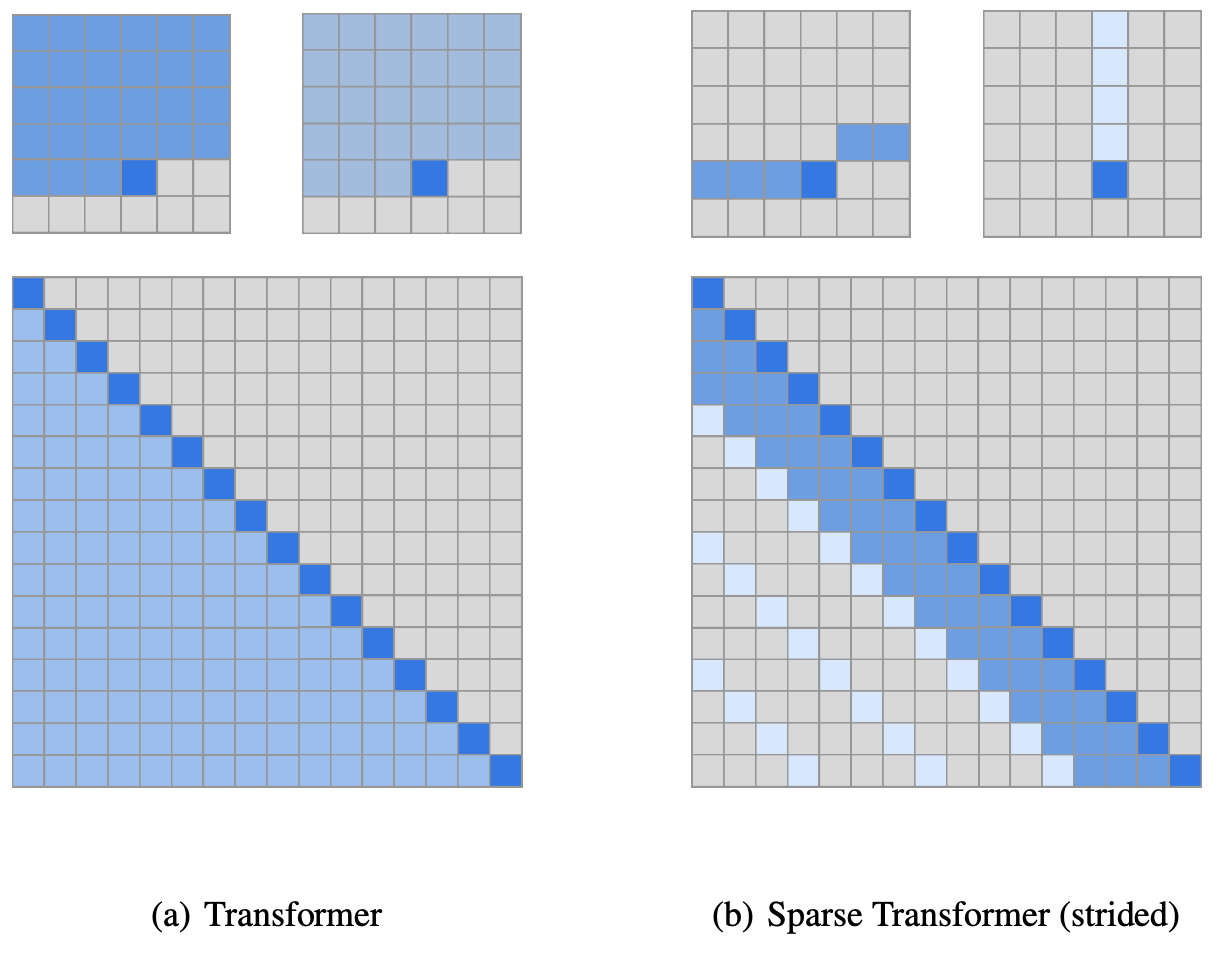
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Language Modelling | 6 | 8.22% |
| Text Classification | 4 | 5.48% |
| Object Detection | 3 | 4.11% |
| Question Answering | 3 | 4.11% |
| Machine Translation | 3 | 4.11% |
| Translation | 3 | 4.11% |
| Image Restoration | 2 | 2.74% |
| Semantic Segmentation | 2 | 2.74% |
| Image Captioning | 2 | 2.74% |
 Adam
Adam
 Attention Dropout
Attention Dropout
 Dense Connections
Dense Connections
 Dropout
Dropout
 Fixed Factorized Attention
Fixed Factorized Attention
 GELU
GELU
 Layer Normalization
Layer Normalization
 Linear Warmup With Cosine Annealing
Linear Warmup With Cosine Annealing
 Multi-Head Attention
Multi-Head Attention
 Residual Connection
Residual Connection
 Scaled Dot-Product Attention
Scaled Dot-Product Attention
 Softmax
Softmax
 Strided Attention
Strided Attention
 Weight Decay
Weight Decay

