 Policy Gradient Methods
Policy Gradient Methods
Stein Variational Policy Gradient
Introduced by Liu et al. in Stein Variational Policy GradientStein Variational Policy Gradient, or SVPG, is a policy gradient based method in reinforcement learning that uses Stein Variational Gradient Descent to allow simultaneous exploitation and exploration of multiple policies. Unlike traditional policy optimization which attempts to learn a single policy, SVPG models a distribution of policy parameters, where samples from this distribution will represent strong policies. SVPG optimizes this distribution of policy parameters with (relative) entropy regularization. The (relative) entropy term explicitly encourages exploration in the parameter space while also optimizing the expected utility of polices drawn from this distribution. Stein variational gradient descent (SVGD) is then used to optimize this distribution. SVGD leverages efficient deterministic dynamics to transport a set of particles to approximate given target posterior distributions.
The update takes the form:
$$ $$
$$ \nabla\theta_i = \frac{1} {n}\sum_{j=1}^n \nabla_{\theta_{j}} \left(\frac{1}{\alpha} J(\theta_{j}) + \log q_0(\theta_j)\right)k(\theta_j, \theta_i) + \nabla_{\theta_j} k(\theta_j, \theta_i)$$
Note that here the magnitude of $\alpha$ adjusts the relative importance between the policy gradient and the prior term $\nabla_{\theta_j} \left(\frac{1}{\alpha} J(\theta_j) + \log q_0(\theta_j)\right)k(\theta_j, \theta_i)$ and the repulsive term $\nabla_{\theta_j} k(\theta_j, \theta_i)$. The repulsive functional is used to diversify particles to enable parameter exploration. A suitable $\alpha$ provides a good trade-off between exploitation and exploration. If $\alpha$ is too large, the Stein gradient would only drive the particles to be consistent with the prior $q_0$. As $\alpha \to 0$, this algorithm is reduced to running $n$ copies of independent policy gradient algorithms, if ${\theta_i}$ are initialized very differently. A careful annealing scheme of $\alpha$ allows efficient exploration in the beginning of training and later focuses on exploitation towards the end of training.
Source: Stein Variational Policy Gradient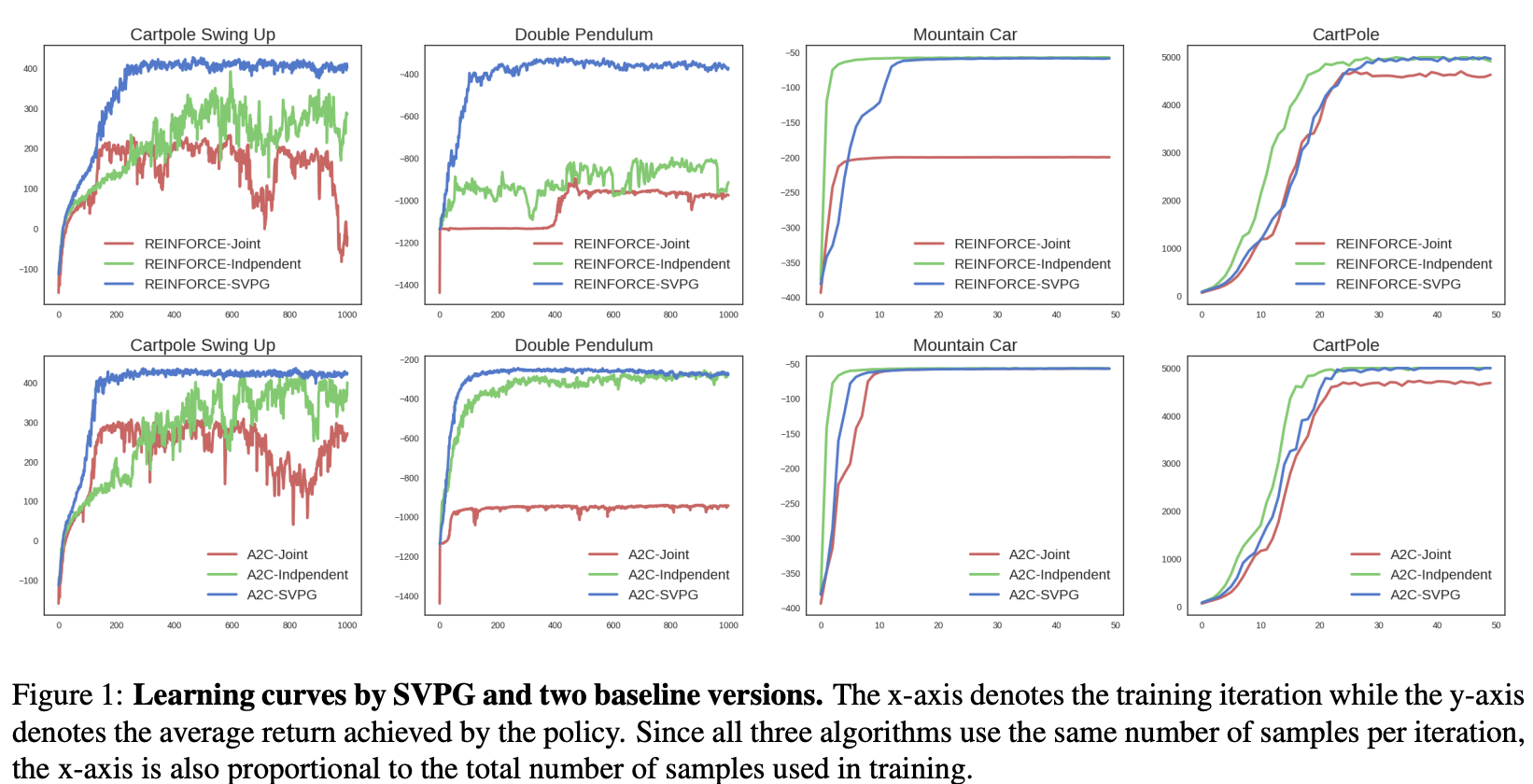
Papers
| Paper | Code | Results | Date | Stars |
|---|
 Adam
Adam
