 Word Embeddings
Word Embeddings
UNiversal Image-TExt Representation Learning
Introduced by Chen et al. in UNITER: UNiversal Image-TExt Representation LearningUNITER or UNiversal Image-TExt Representation model is a large-scale pre-trained model for joint multimodal embedding. It is pre-trained using four image-text datasets COCO, Visual Genome, Conceptual Captions, and SBU Captions. It can power heterogeneous downstream V+L tasks with joint multimodal embeddings. UNITER takes the visual regions of the image and textual tokens of the sentence as inputs. A faster R-CNN is used in Image Embedder to extract the visual features of each region and a Text Embedder is used to tokenize the input sentence into WordPieces.
It proposes WRA via the Optimal Transport to provide more fine-grained alignment between word tokens and image regions that is effective in calculating the minimum cost of transporting the contextualized image embeddings to word embeddings and vice versa.
Four pretraining tasks were designed for this model. They are Masked Language Modeling (MLM), Masked Region Modeling (MRM, with three variants), Image-Text Matching (ITM), and Word-Region Alignment (WRA). This model is different from the previous models because it uses conditional masking on pre-training tasks.
Source: UNITER: UNiversal Image-TExt Representation Learning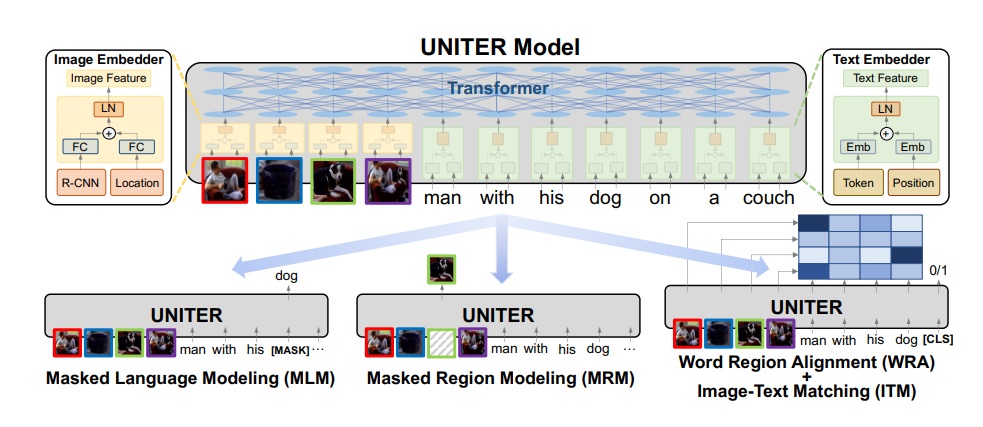
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Referring Expression | 6 | 9.52% |
| Question Answering | 6 | 9.52% |
| Retrieval | 6 | 9.52% |
| Visual Question Answering | 6 | 9.52% |
| Visual Question Answering (VQA) | 5 | 7.94% |
| Language Modelling | 4 | 6.35% |
| Image-text matching | 3 | 4.76% |
| Text Matching | 3 | 4.76% |
| Image Captioning | 3 | 4.76% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
