 Vision and Language Pre-Trained Models
Vision and Language Pre-Trained Models
Vision-and-Langauge Transformer
Introduced by Kim et al. in ViLT: Vision-and-Language Transformer Without Convolution or Region SupervisionViLT is a minimal vision-and-language pre-training transformer model where processing of visual inputs is simplified to just the same convolution-free manner that text inputs are processed. The model-specific components of ViLT require less computation than the transformer component for multimodal interactions. ViLTThe model is pre-trained on the following objectives: image text matching, masked language modeling, and word patch alignment.
Source: ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision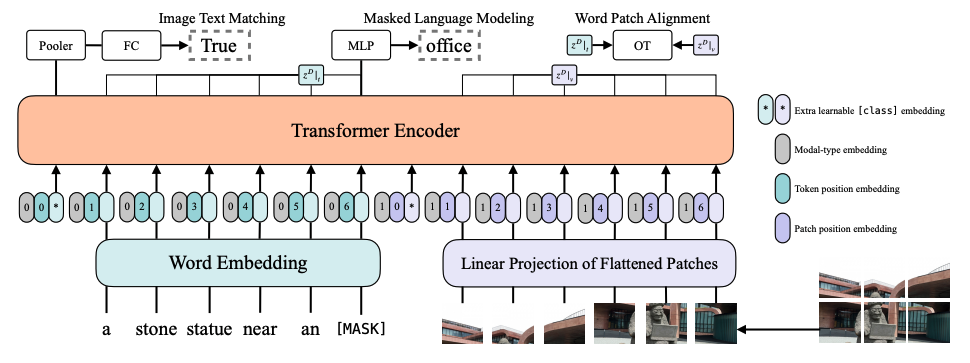
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Visual Question Answering (VQA) | 5 | 9.26% |
| Visual Reasoning | 5 | 9.26% |
| Retrieval | 5 | 9.26% |
| Cross-Modal Retrieval | 3 | 5.56% |
| Image Captioning | 3 | 5.56% |
| Zero-Shot Cross-Modal Retrieval | 3 | 5.56% |
| Question Answering | 3 | 5.56% |
| Visual Question Answering | 3 | 5.56% |
| Visual Entailment | 3 | 5.56% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
