 Instance Segmentation Models
Instance Segmentation Models
VisTR
Introduced by Wang et al. in End-to-End Video Instance Segmentation with TransformersVisTR is a Transformer based video instance segmentation model. It views video instance segmentation as a direct end-to-end parallel sequence decoding/prediction problem. Given a video clip consisting of multiple image frames as input, VisTR outputs the sequence of masks for each instance in the video in order directly. At the core is a new, effective instance sequence matching and segmentation strategy, which supervises and segments instances at the sequence level as a whole. VisTR frames the instance segmentation and tracking in the same perspective of similarity learning, thus considerably simplifying the overall pipeline and is significantly different from existing approaches.
Source: End-to-End Video Instance Segmentation with Transformers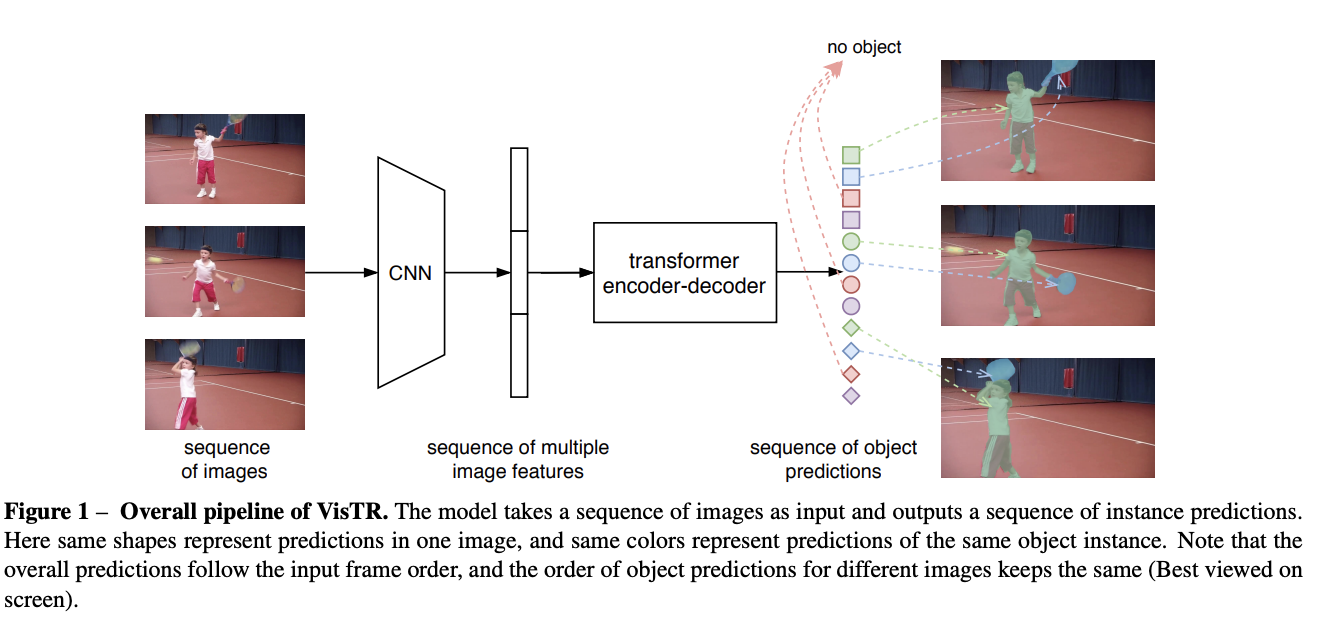
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Instance Segmentation | 3 | 30.00% |
| Semantic Segmentation | 3 | 30.00% |
| Video Instance Segmentation | 3 | 30.00% |
| Video Understanding | 1 | 10.00% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
