 RoI Feature Extractors
RoI Feature Extractors
Voxel RoI Pooling
Introduced by Deng et al. in Voxel R-CNN: Towards High Performance Voxel-based 3D Object DetectionVoxel RoI Pooling is a RoI feature extractor extracts RoI features directly from voxel features for further refinement. It starts by dividing a region proposal into $G \times G \times G$ regular sub-voxels. The center point is taken as the grid point of the corresponding sub-voxel. Since $3 D$ feature volumes are extremely sparse (non-empty voxels account for $<3 \%$ spaces), we cannot directly utilize max pooling over features of each sub-voxel. Instead, features are integrated from neighboring voxels into the grid points for feature extraction. Specifically, given a grid point $g_{i}$, we first exploit voxel query to group a set of neighboring voxels $\Gamma_{i}=\left(\mathbf{v}_{i}^{1}, \mathbf{v}_{i}^{2}, \cdots, \mathbf{v}_{i}^{K}\right) .$ Then, we aggregate the neighboring voxel features with a PointNet module $\mathrm{a}$ as:
$$ \mathbf{\eta}_{i}=\max _{k=1,2, \cdots, K}\left(\Psi\left(\left[\mathbf{v}_{i}^{k}-\mathbf{g}_{i} ; \mathbf{\phi}_{i}^{k}\right]\right)\right) $$
where $\mathbf{v}_{i}-\mathbf{g}_{i}$ represents the relative coordinates, $\mathbf{\phi}_{i}^{k}$ is the voxel feature of $\mathbf{v}_{i}^{k}$, and $\Psi(\cdot)$ indicates an MLP. The max pooling operation $\max (\cdot)$ is performed along the channels to obtain the aggregated feature vector $\eta_{i} .$ Particularly, Voxel RoI pooling is exploited to extract voxel features from the 3D feature volumes out of the last two stages in the $3 \mathrm{D}$ backbone network. And for each stage, two Manhattan distance thresholds are set to group voxels with multiple scales. Then, we concatenate the aggregated features pooled from different stages and scales to obtain the RoI features.
Source: Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection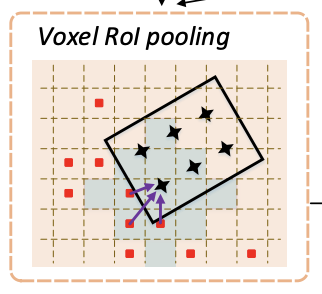
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| 3D Object Detection | 5 | 41.67% |
| Object Detection | 5 | 41.67% |
| Feature Importance | 1 | 8.33% |
| Scene Understanding | 1 | 8.33% |
 Max Pooling
Max Pooling
 PointNet
PointNet
