 Parameter Sharing
Parameter Sharing
Weight Tying
Introduced by Press et al. in Using the Output Embedding to Improve Language ModelsWeight Tying improves the performance of language models by tying (sharing) the weights of the embedding and softmax layers. This method also massively reduces the total number of parameters in the language models that it is applied to.
Language models are typically comprised of an embedding layer, followed by a number of Transformer or LSTM layers, which are finally followed by a softmax layer. Embedding layers learn word representations, such that similar words (in meaning) are represented by vectors that are near each other (in cosine distance). [Press & Wolf, 2016] showed that the softmax matrix, in which every word also has a vector representation, also exhibits this property. This leads them to propose to share the softmax and embedding matrices, which is done today in nearly all language models.
This method was independently introduced by Press & Wolf, 2016 and Inan et al, 2016.
Additionally, the Press & Wolf paper proposes Three-way Weight Tying, a method for NMT models in which the embedding matrix for the source language, the embedding matrix for the target language, and the softmax matrix for the target language are all tied. That method has been adopted by the Attention Is All You Need model and many other neural machine translation models.
Source: Using the Output Embedding to Improve Language Models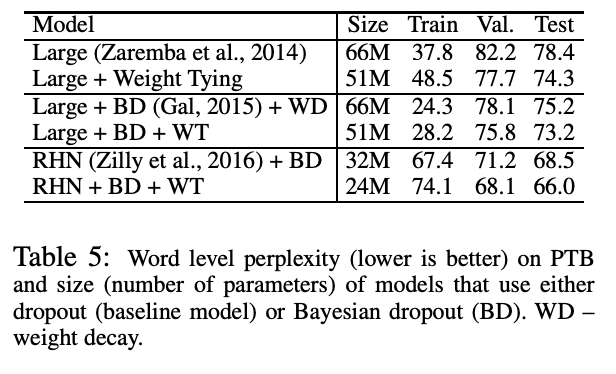
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Language Modelling | 23 | 18.11% |
| General Classification | 15 | 11.81% |
| Text Classification | 13 | 10.24% |
| Classification | 8 | 6.30% |
| Sentiment Analysis | 8 | 6.30% |
| Translation | 7 | 5.51% |
| Machine Translation | 5 | 3.94% |
| Language Identification | 4 | 3.15% |
| Hate Speech Detection | 3 | 2.36% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
