Distributed Methods
General • 43 methods
This section contains a compilation of distributed methods for scaling deep learning to very large models. There are many different strategies for scaling training across multiple devices, including:
-
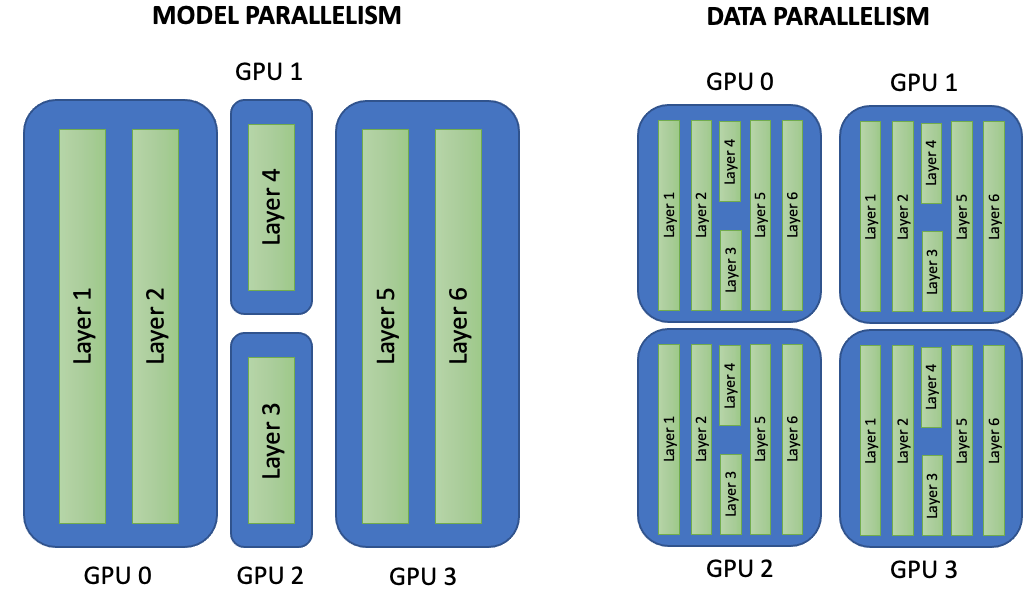
Data Parallel : for each node we use the same model parameters to do forward propagation, but we send a small batch of different data to each node, compute the gradient normally, and send it back to the main node. Once we have all the gradients, we calculate the weighted average and use this to update the model parameters.
-
Model Parallel : for each node we assign different layers to it. During forward propagation, we start in the node with the first layers, then move onto the next, and so on. Once forward propagation is done we calculate gradients for the last node, and update model parameters for that node. Then we backpropagate onto the penultimate node, update the parameters, and so on.
-
Additional methods including Hybrid Parallel, Auto Parallel, and Distributed Communication.
Image credit: Jordi Torres.
Subcategories
Methods
| Method | Year | Papers |
|---|---|---|
| 2018 | 58 | |
| 2019 | 47 | |
| 2017 | 30 | |
| 2018 | 15 | |
| 2021 | 9 | |
| 2018 | 7 | |
| 2020 | 6 | |
| 2019 | 6 | |
| 2020 | 6 | |
| 2018 | 6 | |
| 2020 | 4 | |
| 2019 | 4 | |
| 2020 | 3 | |
| 2020 | 3 | |
| 2019 | 3 | |
| 2019 | 2 | |
| 2019 | 2 | |
| 2020 | 2 | |
| 2018 | 2 | |
| 2021 | 2 | |
| 2019 | 2 | |
| 2020 | 1 | |
| 2019 | 1 | |
| 2019 | 1 | |
| 2021 | 1 | |
| 1 | ||
| 2019 | 1 | |
| 2020 | 1 | |
| 2020 | 1 | |
| 2021 | 1 | |
| 2019 | 1 | |
| 2020 | 1 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2020 | 1 | |
| 2021 | 1 | |
| 2019 | 0 | |
| 2020 | 0 | |
| 2021 | 0 | |
| 2020 | 0 |
 Local SGD
Local SGD
 Parallax
Parallax
 Gradient Sparsification
Gradient Sparsification
 IMPALA
IMPALA
 Chimera
Chimera
 GPipe
GPipe
 GShard
GShard
 ZeRO
ZeRO
 DistDGL
DistDGL
 Tofu
Tofu
 Herring
Herring
 PipeDream
PipeDream
 Accordion
Accordion
 PipeDream-2BW
PipeDream-2BW
 PowerSGD
PowerSGD
 Crossbow
Crossbow
 TorchBeast
TorchBeast
 PyTorch DDP
PyTorch DDP
 Mesh-TensorFlow
Mesh-TensorFlow
 FastMoE
FastMoE
 SEED RL
SEED RL
 Pipelined Backpropagation
Pipelined Backpropagation
 ByteScheduler
ByteScheduler
 PipeMare
PipeMare
 ZeRO-Infinity
ZeRO-Infinity
 Blink Communication
Blink Communication
 PipeTransformer
PipeTransformer
 SlowMo
SlowMo
 AutoSync
AutoSync
 BAGUA
BAGUA
 ZeRO-Offload
ZeRO-Offload
 BytePS
BytePS
 Dorylus
Dorylus
 FlexFlow
FlexFlow
 KungFu
KungFu
 Wavelet Distributed Training
Wavelet Distributed Training
 HetPipe
HetPipe
