Vision Transformers
Computer Vision • Image Models • 45 methods
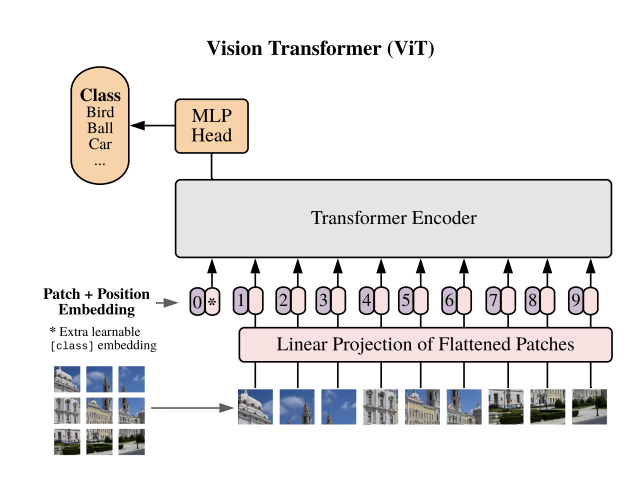
Vision Transformers are Transformer-like models applied to visual tasks. They stem from the work of ViT which directly applied a Transformer architecture on non-overlapping medium-sized image patches for image classification. Below you can find a continually updating list of vision transformers.
According to [1], ViT type models can be further categorized into uniform scale ViTs, multi-scale ViT, hybrid ViTs with convolutions, and self-supervised ViTs. The methods listed below provide a comprehensive overview of ViT models applied to a range of vision tasks.
Methods
| Method | Year | Papers |
|---|---|---|
| 2020 | 1348 | |
| 2021 | 284 | |
| 2020 | 159 | |
| 2021 | 94 | |
| 2020 | 78 | |
| 2020 | 25 | |
| 2021 | 24 | |
| 2021 | 24 | |
| 2021 | 21 | |
| 2021 | 18 | |
| 2021 | 11 | |
| 2021 | 10 | |
| 2021 | 10 | |
| 2021 | 9 | |
| 2021 | 8 | |
| 2021 | 7 | |
| 2021 | 7 | |
| 2021 | 6 | |
| 2021 | 4 | |
| 2021 | 4 | |
| 2021 | 4 | |
| 2021 | 4 | |
| 2021 | 4 | |
| 2021 | 3 | |
| 2021 | 3 | |
| 2021 | 3 | |
| 2020 | 3 | |
| 2021 | 2 | |
| 2021 | 2 | |
| 2021 | 2 | |
| 2021 | 2 | |
| 2021 | 2 | |
| 2022 | 2 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2021 | 1 | |
| 2021 | 1 |
 Vision Transformer
Vision Transformer
 Swin Transformer
Swin Transformer
 Detr
Detr
 DINO
DINO
 DeiT
DeiT
 Deformable DETR
Deformable DETR
 CCT
CCT
 NesT
NesT
 PVT
PVT
 DPT
DPT
 CvT
CvT
 T2T-ViT
T2T-ViT
 MobileViT
MobileViT
 MViT
MViT
 LV-ViT
LV-ViT
 Bottleneck Transformer
Bottleneck Transformer
 MoCo v3
MoCo v3
 TNT
TNT
 PVTv2
PVTv2
 CoaT
CoaT
 CaiT
CaiT
 XCiT
XCiT
 Focal Transformers
Focal Transformers
 CrossViT
CrossViT
 ConViT
ConViT
 MUSIQ
MUSIQ
 CrossTransformers
CrossTransformers
 nnFormer
nnFormer
 VATT
VATT
 LeVIT
LeVIT
 CPVT
CPVT
 CeiT
CeiT
 DeepViT
DeepViT
 OODformer
OODformer
 Colorization Transformer
Colorization Transformer
 Visformer
Visformer
 Twins-PCPVT
Twins-PCPVT
 Twins-SVT
Twins-SVT
 Shuffle-T
Shuffle-T
 RegionViT
RegionViT
 LocalViT
LocalViT
 EsViT
EsViT
 MHMA
MHMA
