Papers with Code Newsletter #3
👋🏻 Welcome to the 3rd issue of the Papers with Code newsletter! In this edition, we highlight 10 novel applications of Transformers, a new leader on the ImageNet leaderboard, a state-of-the-art BERT model, a trillion parameter language model, a novel pooling method, and much more.
Trending Papers with Code 📄
Meta Pseudo Labels [CV]
Self-training or Pseudo Label methods have been used to improve performance in computer vision tasks. With these methods, a teacher network is trained to improve a student network. While effective, the drawback of existing methods is that the teacher remains fixed, thus unable to inform the student of inaccuracies coming from inaccurate pseudo labels - the confirmation bias problem in pseudo-labeling.
What's new: Pham et al. propose a semi-supervised learning method, Meta Pseudo Labels, for image classification where a teacher network is trained to generate pseudo labels on unlabeled data to train a student network. Meta Pseudo Labels adapts the teacher network with the performance of the student network on the labeled dataset. This work claims improvements on ImageNet with a 90.2% top-1 accuracy.

Denotes the difference between Pseudo Labels (left) and Meta Pseudo Labels (right). Meta Pseudo Labels shows the teacher being trained along with the student. (Figure source: Pham et al. (2020))
Scaling to Trillion Parameter NLP Models [NLP]
Large scale neural language models have been used to obtain strong performance on a range of NLP tasks, but they are computationally intensive! Mixture of Experts (MoE) models are one approach to scale models through sparse activations, but their use is hindered by communication cost and training instabilities.
Why it matters: Fedus et al. propose the Switch Transformer (based on T5) which simplifies the MoE routing algorithm resulting in a model that scales pre-training to a trillion parameters (!). It achieves greater computational efficiency to support scaling on three NLP regimes: pre-training, fine-tuning, and multi-task training. It claims a 7x speedup in pre-training with the same computational resources used by T5 variants. Authors also report improvements on multilingual data across 101 languages and enhanced distilled models.
![]()
Illustration of a Switch Transformer encoder block where the router independently routes each token across four FFNs. (Figure source: Fedus et al. (2020))
DeBERTa sits atop the SuperGLUE Benchmark [NLP]
There are ongoing efforts to improve the generalization and efficiency of language models like BERT and RoBERTa. DeBERTa (Decoding enhanced BERT with disentangled attention) is a new architecture based on a disentangled attention mechanism and an enhanced mask decoder.
What’s new: DeBERTa calculates attention weights for words using disentangled matrices of word content and relative positions. The architecture also makes use of the absolute position of words, after all Transformer layers and before the softmax layer, as complementary information to decode masked words. DeBERTA is pre-trained using masked language modeling and fine-tuned using a new virtual adversarial training method. The result is improved performance on many downstream tasks. It is currently the top-performing model on SuperGLUE.
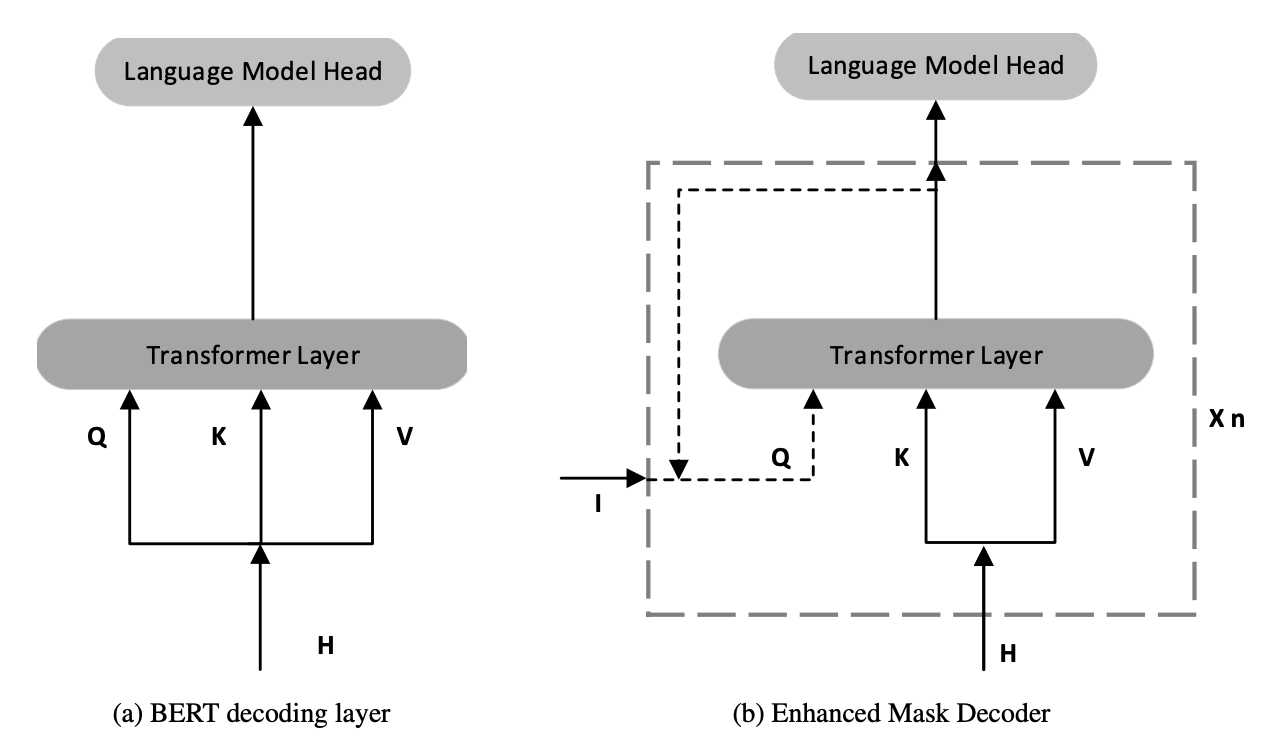
Comparison of the decoding layer of vanilla BERT (left) and proposed Enhanced Mask Decoder (right).
Making VGG-style ConvNets Great Again [CV]
VGG-style ConvNets, although now considered a a classic architecture, were attractive due to their simplicity. In contrast, ResNets have become popular due to their high accuracy but are more difficult to customize and display undesired inference drawbacks. To address these issues, Ding et al. propose RepVGG - the return of the VGG!
What's new: RepVGG is an efficient and simple architecture using plain VGG-style ConvNets. It decouples the inference-time and training-time architecture through a structural re-parameterization technique. Authors report favorable speed-accuracy tradeoff compared to state-of-the-art models, such as EfficientNet and RegNet. RepVGG achieves 80% top-1 accuracy on ImageNet and is benchmarked as being 83% faster than ResNet-50. This research is part of a broader effort to build more efficient models using simpler architectures and operations.

Architecture of RepVGG at inference-time (B) and training-time (C). (Figure source: Ding et al. (2020))
A New Pooling Method for CNN Architectures [DL]
Pooling methods in CNNs decrease the size of the activation maps helping to achieve spatial invariance and increase the receptive field. This paper seeks to improve pooling methods by minimizing loss of information while keeping the memory and computation overhead limited.
Why it matters: Stergiou et al. propose SoftPool which is a novel pooling method that's fast, memory-efficient, and better preserves features when downsampling. The authors report that the refined downsampling of SoftPool produces consistent accuracy improvements - when using popular CNN architectures for image classification and action recognition.
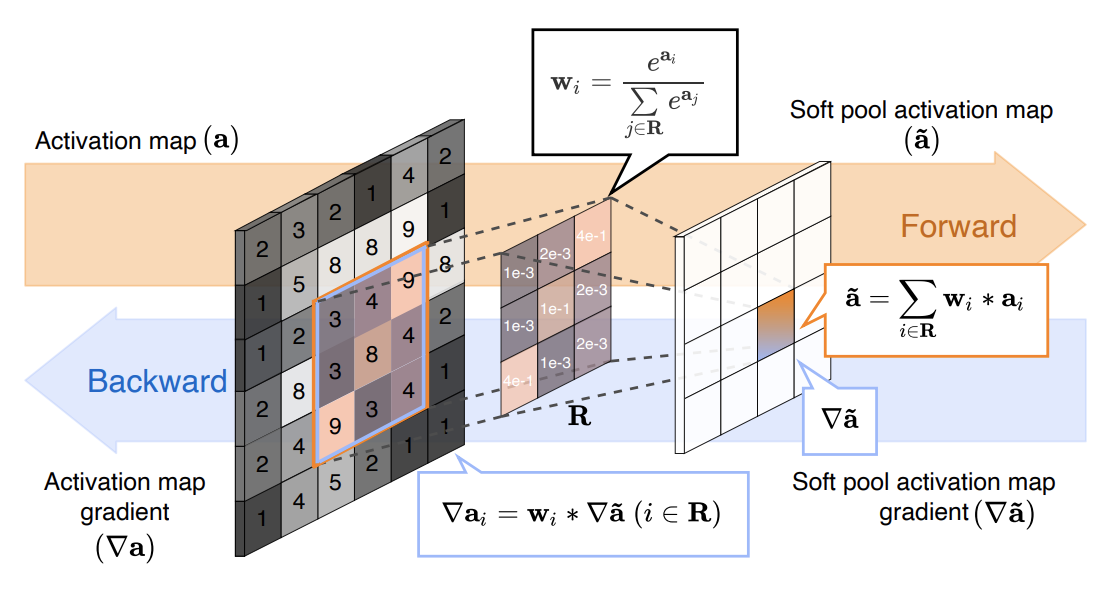
Overview of SoftPool operation. (Figure source: Stergiou et al. (2020))
10 Novel Applications using Transformers [DL]
Transformers have had a lot of success in training neural language models. In the past few weeks, we've seen several trending papers with code applying Transformers to new types of task:
🏞 Transformer for Image Synthesis - 🔗 Esser et al. (2020)
🖲 Transformer for Multi-Object Tracking - 🔗 Sun et al. (2020)
🎶 Transformer for Music Generation - 🔗 Hsiao et al. (2021)
💃 Transformer for Dance Generation with Music - 🔗 Huang et al. (2021)
🔮 Transformer for 3D Object Detection - 🔗 Bhattacharyya et al. (2021)
🗿 Transformer for Point-Cloud Processing - 🔗 Guo et al. (2020)
⏰ Transformer for Time-Series Forecasting - 🔗 Lim et al. (2020)
👁 Transformer for Vision-Language Modeling - 🔗 Zhang et al. (2021)
🛣 Transformer for Lane Shape Prediction - 🔗 Liu et al. (2020)
🌠 Transformer for End-to-End Object Detection - 🔗 Zhu et al. (2021)
Trending Libraries and Datasets 🛠
Trending libraries of the week:
TextBox - a unified framework implemented on top of PyTorch that provides modules for text generation tasks and models. TextBox makes accessible text generation models (e.g., GAN-based and pretrained language models) on benchmark datasets.
Trending with 196 ★
Trankit - a Python toolkit with trainable pipelines for fundamental NLP tasks for over 100 languages. Built for efficient use of language models.
Trending with 190 ★
CRSLab - an open-source toolkit for building conversational recommender systems.
Trending with 146 ★
PyHealth - is a toolkit that aims to address the reproducibility issues in healthcare AI research, such as lack of standard benchmark datasets and evaluation metrics.
Trending with 292 ★
FaceX-Zoo - a unified toolbox to support features for deep face recognition and providing automatic evaluation with different models on multiple benchmarks.
Trending with 252 ★
Trending datasets of the week:
OpenViDial - a large-scale, multi-modal dialogue dataset containing 1.1 million utterances paired with visual contexts.
Trending with 51 ★
The Pile - a large and diverse text corpus (800GB) to train language models. It aims to improve cross-domain knowledge and generalization on downstream tasks.
Trending with 306 ★
Community Highlights ✍️
The following are some of the community highlights for this week:
- Thanks to @matthiassamwald and Kathrin Blagec for adding 100+ task descriptions to Papers with Code! This is part of their ontology building project.
- Thanks Rosalie Schneider for improving tasks and benchmark results for their work on self-supervised multimodal networks applied to action recognition.
- Thanks to Yuejiang Liu for improving tasks and results for their work on trajectory projection.
- Thanks to @aashukha for several code submissions to papers.
- Thanks to Malik Boudiaf for adding several benchmarks results to Papers with Code.
Special thanks to users @htvr, @tienduang, @rrafikova, @donovanOng, @maksymets, @humamalwassel, @zhaochengqi and hundreds of other contributors for several contributions to Papers with Code tasks, methods, and benchmarks results.
More from PwC 🗣
ICLR 2021 Papers with Code - ICLR 2021 papers with code are out! You can filter papers by task, author, keyword, and much more.
We would be happy to hear your thoughts, feedback and suggestions on the newsletter. Please reach out to elvis@paperswithcode.com.
Join the community: Slack | Twitter
