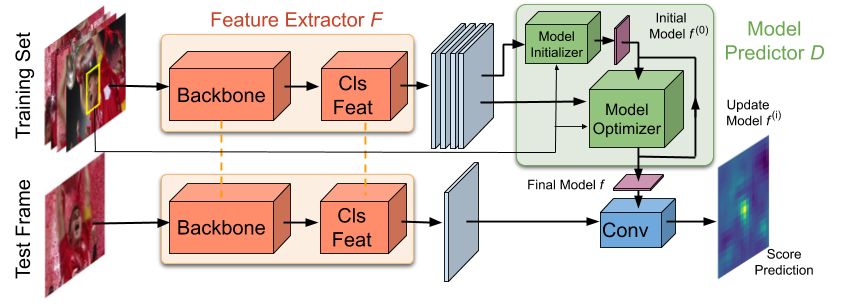
Learning Discriminative Model Prediction for Tracking
The current strive towards end-to-end trainable computer vision systems imposes major challenges for the task of visual tracking. In contrast to most other vision problems, tracking requires the learning of a robust target-specific appearance model online, during the inference stage. To be end-to-end trainable, the online learning of the target model thus needs to be embedded in the tracking architecture itself. Due to the imposed challenges, the popular Siamese paradigm simply predicts a target feature template, while ignoring the background appearance information during inference. Consequently, the predicted model possesses limited target-background discriminability. We develop an end-to-end tracking architecture, capable of fully exploiting both target and background appearance information for target model prediction. Our architecture is derived from a discriminative learning loss by designing a dedicated optimization process that is capable of predicting a powerful model in only a few iterations. Furthermore, our approach is able to learn key aspects of the discriminative loss itself. The proposed tracker sets a new state-of-the-art on 6 tracking benchmarks, achieving an EAO score of 0.440 on VOT2018, while running at over 40 FPS. The code and models are available at https://github.com/visionml/pytracking.
PDF Abstract ICCV 2019 PDF ICCV 2019 Abstract


 OTB
OTB
 LaSOT
LaSOT
 GOT-10k
GOT-10k
 TrackingNet
TrackingNet
 VOT2018
VOT2018
