Speech2Face: Learning the Face Behind a Voice
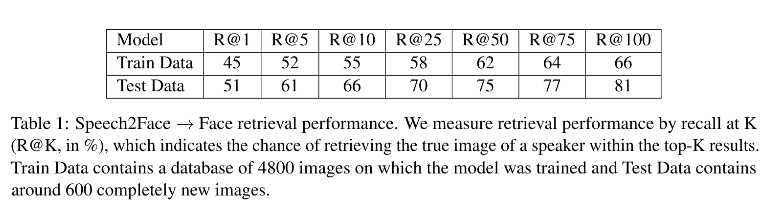
How much can we infer about a person's looks from the way they speak? In this paper, we study the task of reconstructing a facial image of a person from a short audio recording of that person speaking. We design and train a deep neural network to perform this task using millions of natural Internet/YouTube videos of people speaking. During training, our model learns voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity. This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how--and in what manner--our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.
PDF Abstract CVPR 2019 PDF CVPR 2019 Abstract

 AVSpeech
AVSpeech
