Adversarial Robustness as a Prior for Learned Representations
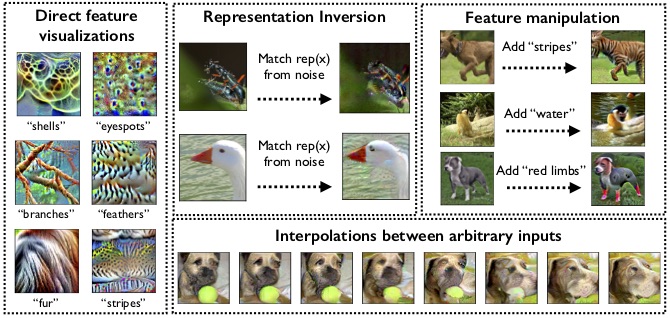
An important goal in deep learning is to learn versatile, high-level feature representations of input data. However, standard networks' representations seem to possess shortcomings that, as we illustrate, prevent them from fully realizing this goal. In this work, we show that robust optimization can be re-cast as a tool for enforcing priors on the features learned by deep neural networks. It turns out that representations learned by robust models address the aforementioned shortcomings and make significant progress towards learning a high-level encoding of inputs. In particular, these representations are approximately invertible, while allowing for direct visualization and manipulation of salient input features. More broadly, our results indicate adversarial robustness as a promising avenue for improving learned representations. Our code and models for reproducing these results is available at https://git.io/robust-reps .
PDF Abstract

