CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
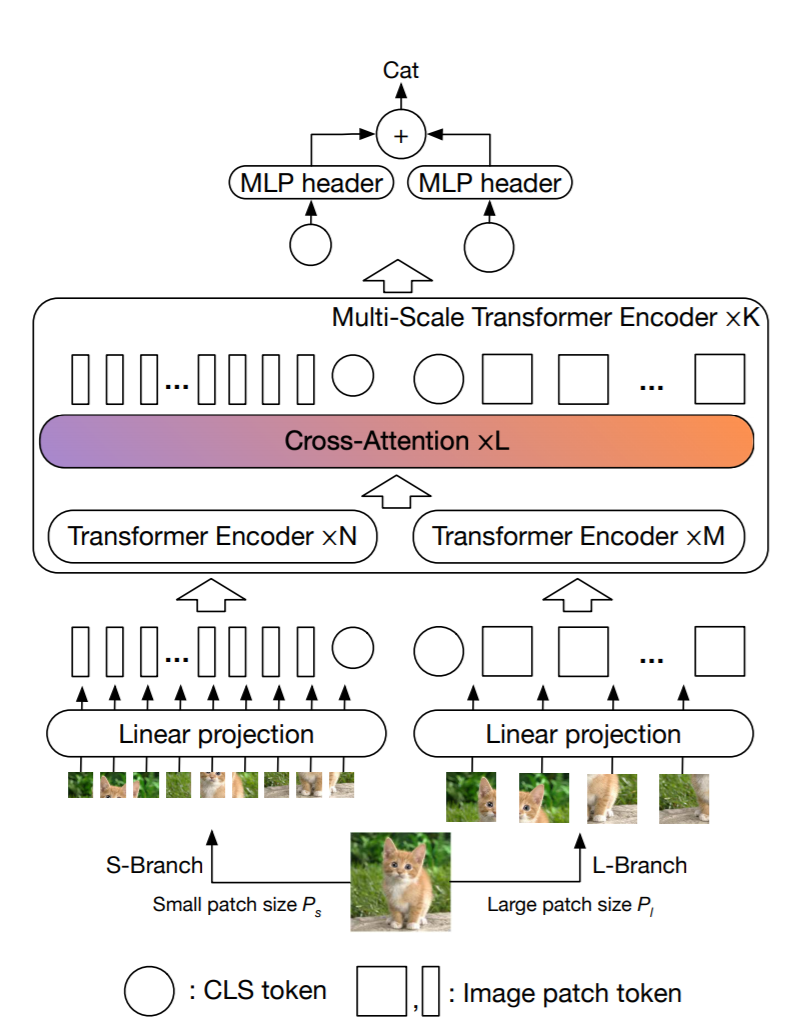
The recently developed vision transformer (ViT) has achieved promising results on image classification compared to convolutional neural networks. Inspired by this, in this paper, we study how to learn multi-scale feature representations in transformer models for image classification. To this end, we propose a dual-branch transformer to combine image patches (i.e., tokens in a transformer) of different sizes to produce stronger image features. Our approach processes small-patch and large-patch tokens with two separate branches of different computational complexity and these tokens are then fused purely by attention multiple times to complement each other. Furthermore, to reduce computation, we develop a simple yet effective token fusion module based on cross attention, which uses a single token for each branch as a query to exchange information with other branches. Our proposed cross-attention only requires linear time for both computational and memory complexity instead of quadratic time otherwise. Extensive experiments demonstrate that our approach performs better than or on par with several concurrent works on vision transformer, in addition to efficient CNN models. For example, on the ImageNet1K dataset, with some architectural changes, our approach outperforms the recent DeiT by a large margin of 2\% with a small to moderate increase in FLOPs and model parameters. Our source codes and models are available at \url{https://github.com/IBM/CrossViT}.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract


 Colab
Colab



 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 JFT-300M
JFT-300M

