3D human pose estimation in video with temporal convolutions and semi-supervised training
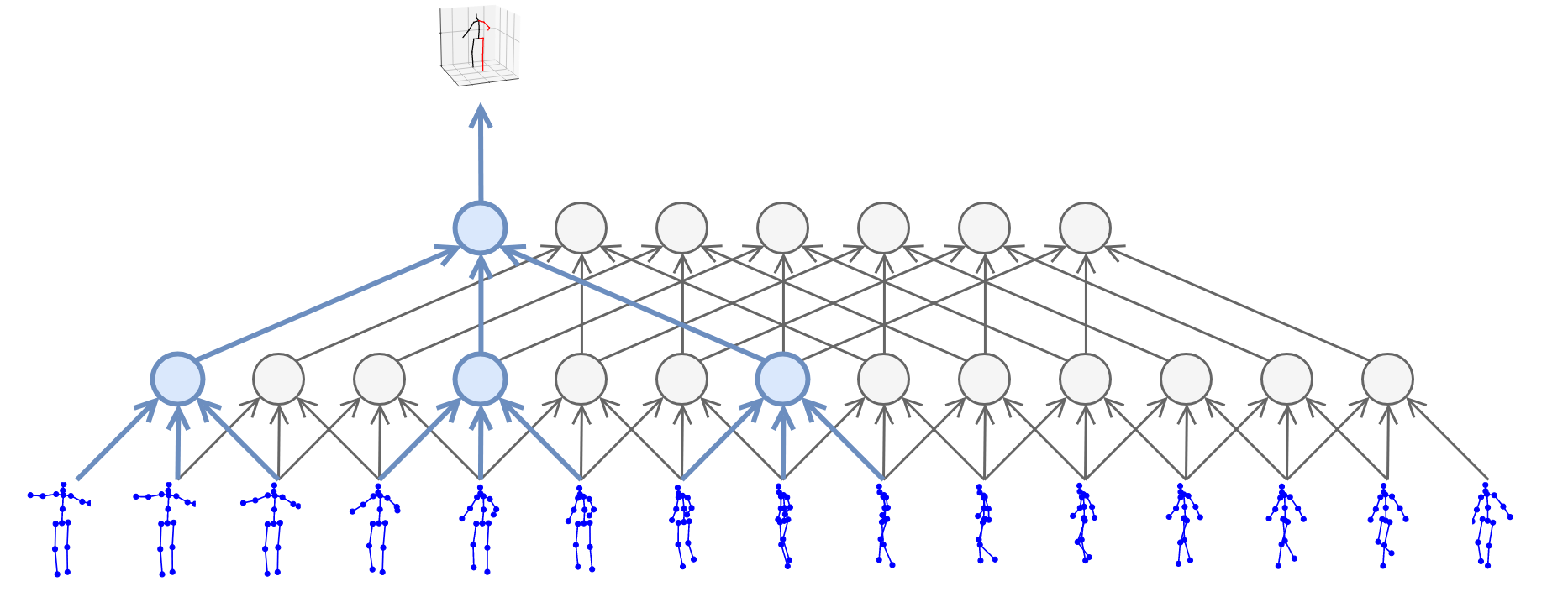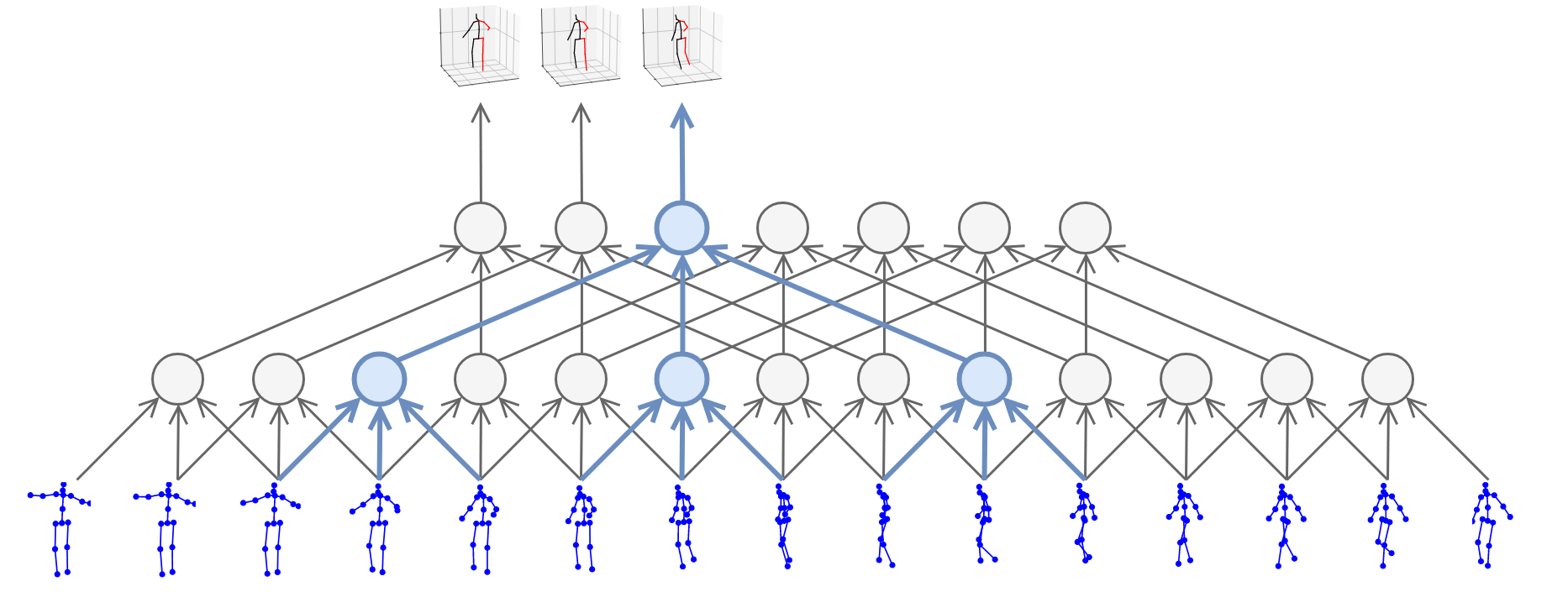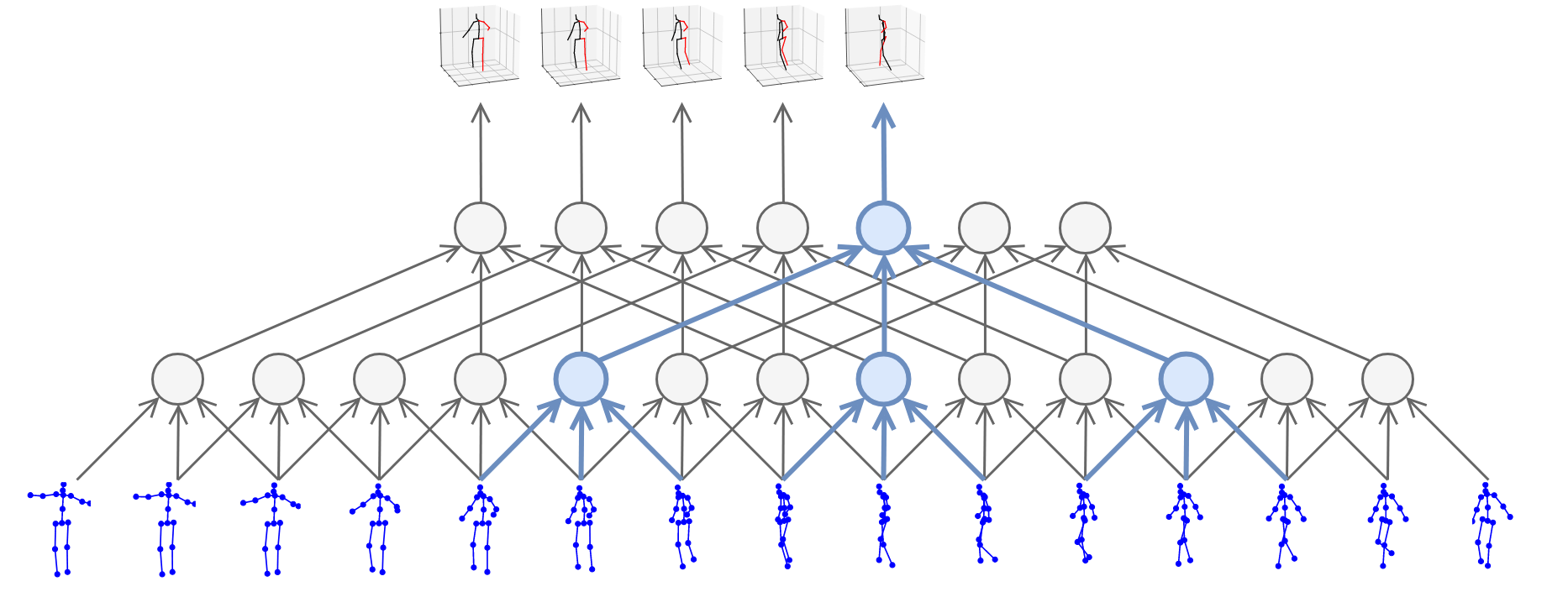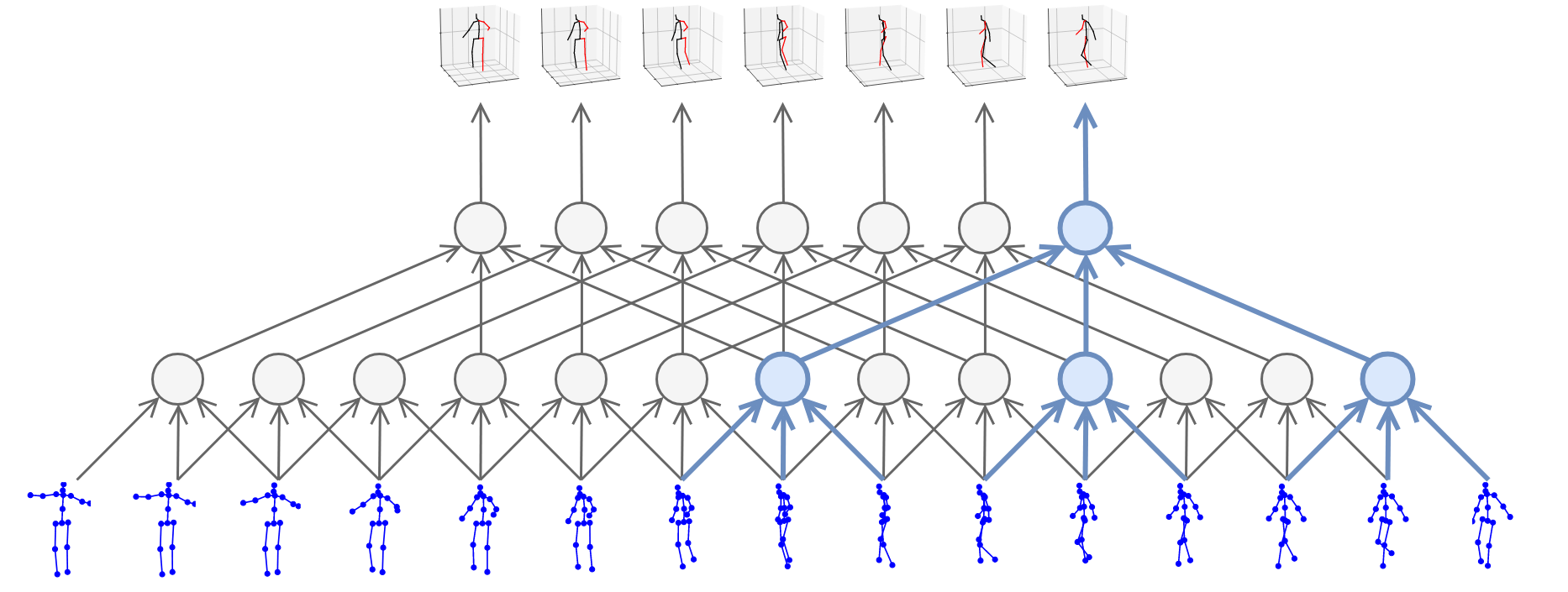
In this work, we demonstrate that 3D poses in video can be effectively estimated with a fully convolutional model based on dilated temporal convolutions over 2D keypoints. We also introduce back-projection, a simple and effective semi-supervised training method that leverages unlabeled video data. We start with predicted 2D keypoints for unlabeled video, then estimate 3D poses and finally back-project to the input 2D keypoints. In the supervised setting, our fully-convolutional model outperforms the previous best result from the literature by 6 mm mean per-joint position error on Human3.6M, corresponding to an error reduction of 11%, and the model also shows significant improvements on HumanEva-I. Moreover, experiments with back-projection show that it comfortably outperforms previous state-of-the-art results in semi-supervised settings where labeled data is scarce. Code and models are available at https://github.com/facebookresearch/VideoPose3D
PDF Abstract CVPR 2019 PDF CVPR 2019 AbstractCode




 MS COCO
MS COCO
 Human3.6M
Human3.6M
Results from the Paper
 Ranked #13 on
Weakly-supervised 3D Human Pose Estimation
on Human3.6M
(Number of Frames Per View metric)
Ranked #13 on
Weakly-supervised 3D Human Pose Estimation
on Human3.6M
(Number of Frames Per View metric)
