3D Sketch-aware Semantic Scene Completion via Semi-supervised Structure Prior
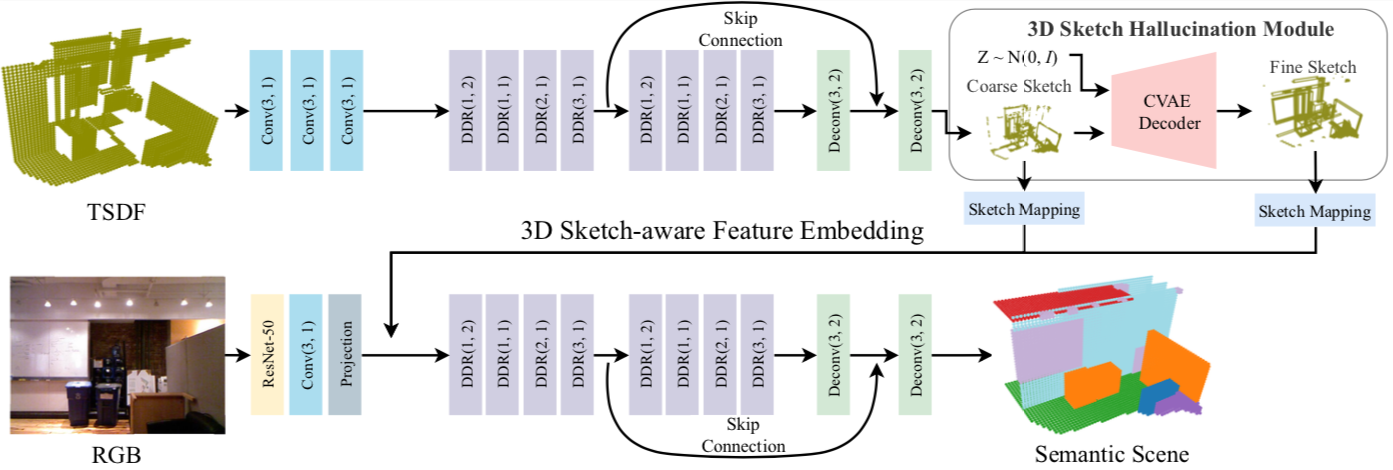
The goal of the Semantic Scene Completion (SSC) task is to simultaneously predict a completed 3D voxel representation of volumetric occupancy and semantic labels of objects in the scene from a single-view observation. Since the computational cost generally increases explosively along with the growth of voxel resolution, most current state-of-the-arts have to tailor their framework into a low-resolution representation with the sacrifice of detail prediction. Thus, voxel resolution becomes one of the crucial difficulties that lead to the performance bottleneck. In this paper, we propose to devise a new geometry-based strategy to embed depth information with low-resolution voxel representation, which could still be able to encode sufficient geometric information, e.g., room layout, object's sizes and shapes, to infer the invisible areas of the scene with well structure-preserving details. To this end, we first propose a novel 3D sketch-aware feature embedding to explicitly encode geometric information effectively and efficiently. With the 3D sketch in hand, we further devise a simple yet effective semantic scene completion framework that incorporates a light-weight 3D Sketch Hallucination module to guide the inference of occupancy and the semantic labels via a semi-supervised structure prior learning strategy. We demonstrate that our proposed geometric embedding works better than the depth feature learning from habitual SSC frameworks. Our final model surpasses state-of-the-arts consistently on three public benchmarks, which only requires 3D volumes of 60 x 36 x 60 resolution for both input and output. The code and the supplementary material will be available at https://charlesCXK.github.io.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract



 NYUv2
NYUv2
 SemanticKITTI
SemanticKITTI
 SUNCG
SUNCG

