Span-based Localizing Network for Natural Language Video Localization
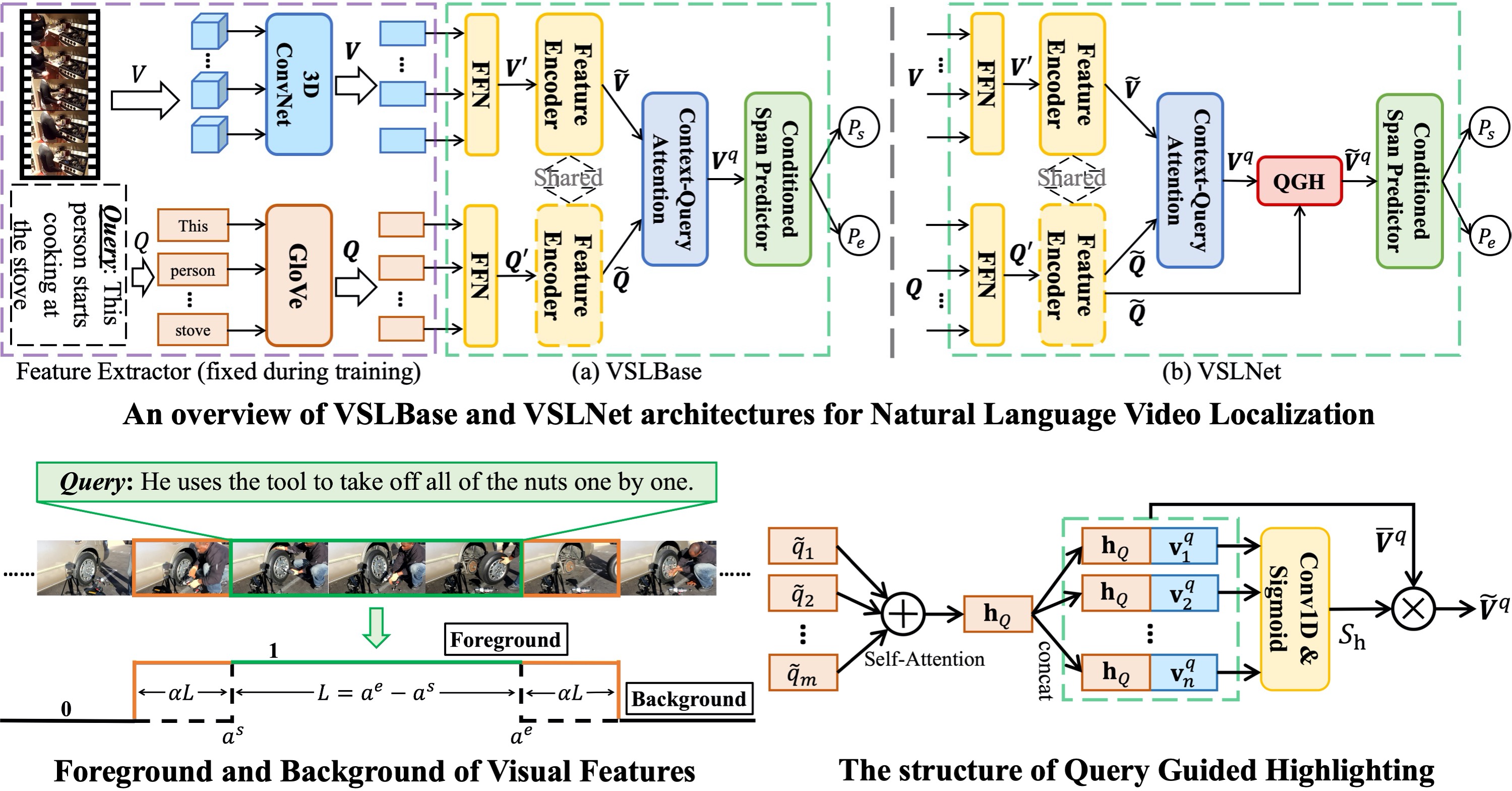
Given an untrimmed video and a text query, natural language video localization (NLVL) is to locate a matching span from the video that semantically corresponds to the query. Existing solutions formulate NLVL either as a ranking task and apply multimodal matching architecture, or as a regression task to directly regress the target video span. In this work, we address NLVL task with a span-based QA approach by treating the input video as text passage. We propose a video span localizing network (VSLNet), on top of the standard span-based QA framework, to address NLVL. The proposed VSLNet tackles the differences between NLVL and span-based QA through a simple yet effective query-guided highlighting (QGH) strategy. The QGH guides VSLNet to search for matching video span within a highlighted region. Through extensive experiments on three benchmark datasets, we show that the proposed VSLNet outperforms the state-of-the-art methods; and adopting span-based QA framework is a promising direction to solve NLVL.
PDF Abstract ACL 2020 PDF ACL 2020 Abstract
 ActivityNet
ActivityNet
 Charades
Charades
 Charades-STA
Charades-STA
