GenAug: Data Augmentation for Finetuning Text Generators
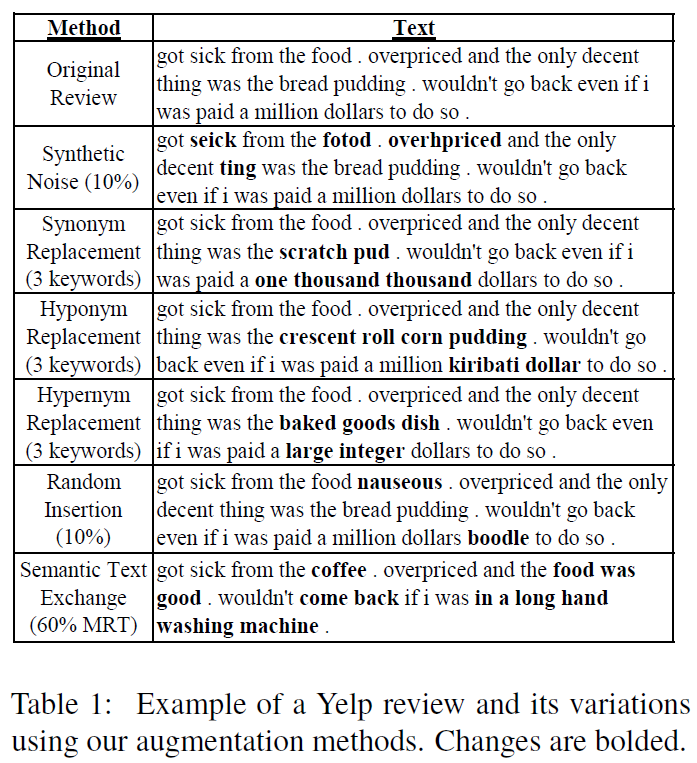
In this paper, we investigate data augmentation for text generation, which we call GenAug. Text generation and language modeling are important tasks within natural language processing, and are especially challenging for low-data regimes. We propose and evaluate various augmentation methods, including some that incorporate external knowledge, for finetuning GPT-2 on a subset of Yelp Reviews. We also examine the relationship between the amount of augmentation and the quality of the generated text. We utilize several metrics that evaluate important aspects of the generated text including its diversity and fluency. Our experiments demonstrate that insertion of character-level synthetic noise and keyword replacement with hypernyms are effective augmentation methods, and that the quality of generations improves to a peak at approximately three times the amount of original data.
PDF Abstract EMNLP (DeeLIO) 2020 PDF EMNLP (DeeLIO) 2020 Abstract



 WebText
WebText
